Votre Audit de site ne fonctionne pas correctement ?
En fonction de la configuration et de la structure de votre site, plusieurs raisons peuvent expliquer le blocage du robot d’exploration d’Audit de site :
- Le fichier robots.txt bloque le robot d’indexation
- La portée de l’exploration exclut certaines parties du site
- Le site Web n’est pas accessible directement en raison de l’hébergement partagé
- La taille de la page de destination dépasse 2 Mo
- Les pages se trouvent derrière une passerelle ou une partie du site réservées à certains utilisateurs
- Une balise noindex bloque le robot d’exploration
- Le domaine n’a pas pu être résolu par le DNS — le domaine saisi dans la configuration est hors ligne
- Le contenu du site Web est développé en JavaScript — bien que Site Audit puisse interpréter le code JavaScript, il peut encore être à l’origine de certains problèmes
Étapes de dépannage
Suivez ces étapes de dépannage pour essayer de résoudre le problème par vous-même avant de contacter notre service d’assistance pour obtenir de l’aide.
Un fichier robots.txt donne des instructions aux robots sur la manière d’explorer (ou de ne pas explorer) les pages d’un site Web. Dans ce fichier, vous pouvez autoriser ou interdire aux robots tels que Googlebot ou Semrushbot d’explorer l’ensemble de votre site ou des zones spécifiques de votre site en utilisant des commandes telles que Allow, Disallow, et Crawl Delay.
Si votre fichier robots.txt n’autorise par l’exploration de votre site par notre robot, l’outil Audit de site ne pourra pas l’analyser.
Commencez par inspecter votre fichier robots.txt à la recherche de commandes « Disallow » qui pourraient empêcher les robots d’exploration comme le nôtre d’accéder à votre site Web.
Pour permettre au robot d’Audit de site de Semrush (SiteAuditBot) d’explorer votre site, ajoutez les paramètres suivants à votre fichier robots.txt :
User-agent: SiteAuditBot
Disallow:
(laissez un espace vide après « Disallow »)
Voici un exemple de fichier robots.txt :

Comme vous pouvez le voir, différentes commandes sont définies en fonction du « user agent » (robot d’exploration) auquel le fichier s’adresse.
Ces fichiers sont publics et doivent être hébergés à la racine d’un site pour être trouvés. Pour trouver le fichier robots.txt d’un site Web, saisissez le domaine racine du site suivi de /robots.txt dans la barre de recherche de votre navigateur. Par exemple, le fichier robots.txt de Semrush.com se trouve à l’adresse https://semrush.com/robots.txt.
Voici quelques termes que vous pouvez trouver dans un fichier robots.txt :
- User-Agent = le robot d’exploration à qui les commandes sont adressées.
- Par exemple : SiteAuditBot, Googlebot
- Allow = une commande (seulement pour Googlebot) qui indique au robot qu’il peut explorer une page ou une zone spécifique d’un site Web, même si la page ou le dossier parent ne lui est pas accessible.
- Disallow = une commande qui indique au robot d’exploration de ne pas explorer une URL ou un sous-dossier spécifique d’un site.
- Par exemple : Disallow: /admin/
- Crawl Delay = une commande qui indique aux robots combien de secondes ils doivent attendre avant de charger et d’explorer une autre page.
- Sitemap = indique où se trouve le fichier sitemap.xml d’une URL donnée.
- /= utilisez le symbole « / » après une commande Disallow pour indiquer au robot de ne pas explorer l’intégralité de votre site
- * = un caractère générique qui représente n’importe quelle chaîne de caractères possible dans une URL, utilisé pour indiquer une zone d’un site ou tous les user agents.
- Par exemple : /blog/* indique toutes les URL du sous-dossier blog d’un site Web
- Par exemple : User-agent: * indique que les instructions qui suivent sont adressées à tous les robots
Vous pouvez en apprendre davantage sur les spécifications du fichier robots.txt sur Google ou sur le blog Semrush.
Si vous trouvez le code suivant sur la page principale d’un site Web, cela indique que nous ne sommes pas autorisés à indexer/suivre les liens présents sur la page, et notre accès est bloqué.
<meta name="robots" content="noindex, nofollow" >
De même, une page contenant au moins l’un des éléments suivants : « noindex», « nofollow», « none », entraînera une erreur lors de l’exploration
Pour permettre à notre robot d’explorer une telle page, retirez ces balises « noindex » du code de votre page. Pour plus d’informations sur la balise noindex, veuillez consulter cet article de l’Aide Google.
Pour mettre le robot sur liste blanche, contactez votre webmaster ou hébergeur et demandez-leur de mettre SiteAuditBot sur liste blanche.
L’adresse IP du robot est : 85.208.98.128/25 (un sous-réseau utilisé uniquement par Audit de site)
Le robot utilise les ports standards 80 HTTP et 443 HTTPS pour se connecter.
Si vous utilisez des plug-ins (Wordpress par exemple) ou des RDC (réseau de diffusion de contenu) pour gérer votre site, vous devrez également mettre l’IP du robot sur liste blanche au sein de ces derniers.
Pour l’ajout à la liste blanche sur Wordpress, veuillez contacter le service d’assistance de Wordpress.
Les RDC les plus courants qui bloquent notre robot d’exploration sont les suivants :
- Cloudflare – voir comment mettre sur liste blanche ici
- Imperva – voir comment mettre sur liste blanche ici
- ModSecurity – voir comment mettre sur liste blanche ici
- Sucuri – voir comment mettre sur liste blanche ici
Remarque : si vous disposez d’un hébergement partagé, il est possible que votre hébergeur ne vous autorise pas à mettre des robots en liste blanche ou à modifier le fichier robots.txt.
Fournisseurs d’hébergement
Vous trouverez ci-dessous une liste des fournisseurs d’hébergement les plus populaires sur le Web et des instructions sur comment mettre un robot en lite blanche ou contacter l’assistance pour chacun d’eux :
- Siteground – instructions de mise sur liste blanche
- 1&1 IONOS – instructions de mise sur liste blanche
- Bluehost* – instructions de mise sur liste blanche
- Hostgator* – instructions de mise sur liste blanche
- Hostinger – instructions de mise sur liste blanche
- GoDaddy – instructions de mise sur liste blanche
- GreenGeeks – instructions de mise sur liste blanche
- Big Commerce – vous devez contacter l’assistance
- Liquid Web – vous devez contacter l’assistance
- iPage – vous devez contacter l’assistance
- InMotion – vous devez contacter l’assistance
- Glowhost – vous devez contacter l’assistance
- Hosting – vous devez contacter l’assistance
- DreamHost – vous devez contacter l’assistance
* Remarque : ces instructions fonctionnent pour HostGator et Bluehost si votre site Web se trouve sur un serveur VPS ou un hébergement dédié.
Si la taille de votre page de destination ou la taille totale des fichiers JavaScript/CSS dépasse 2 Mo, nos robots d'exploration ne pourront pas la traiter en raison des limitations techniques de l'outil.
Pour en savoir plus sur la cause possible de l'augmentation de la taille et la résolution de ce problème, référez-vous à cet article de notre blog.
Pour savoir combien de votre budget d’exploration a été utilisé, accédez à Profil—Infos abonnement et recherchez « Pages à explorer » sous « Boîte à outils SEO ».
En fonction de votre forfait, vous bénéficiez d’un nombre déterminé de pages à explorer par mois (budget d’exploration mensuel). Une fois cette limite atteinte, vous devrez acheter des unités d'utilisation supplémentaires ou attendre la réinitialisation de votre budget d’exploration le mois suivant.
Si le message d'erreur « Vous avez atteint la limite de campagnes pouvant être exécutées simultanément » s'affiche pendant la configuration, cela signifie que vous avez atteint la limite d'audits réalisables en même temps prévue par votre forfait.
Nos différents forfaits prévoient les limites suivantes :
- compte gratuit — 1 audit de site à la fois ;
- boîte à outils SEO Pro — jusqu'à 2 audits de site simultanément ;
- boîte à outils SEO Guru — jusqu'à 2 audits de site simultanément ;
- boîte à outils SEO Business — jusqu'à 5 audits de site simultanément.
Si le domaine ne peut pas être résolu par le DNS, cela signifie probablement que le domaine que vous avez saisi lors de la configuration est hors ligne. Généralement, les utilisateurs rencontrent ce problème lorsqu’ils saisissent un domaine racine (exemple.com) sans se rendre compte que la version du domaine racine de leur site n’existe pas, et qu’ils doivent plutôt saisir la version avec « www » de leur site (www.exemple.com).
Pour éviter ce problème, le propriétaire du site Web peut ajouter une redirection depuis le site non sécurisé « exemple.com » vers le site sécurisé « www.exemple.com » qui existe sur le serveur. Ce problème peut également se produire dans l’autre sens, si le domaine racine est sécurisé, mais que la version « www » ne l’est pas. Dans ce cas, il suffit de rediriger la version WWW vers le domaine racine.
Si votre page d’accueil contient des liens vers le reste de votre site cachés dans des éléments JavaScript, vous devez activer le rendu JS afin que nous puissions y accéder et explorer ces pages. Cette fonctionnalité est disponible avec les forfaits Guru et Business de la boîte à outils SEO.
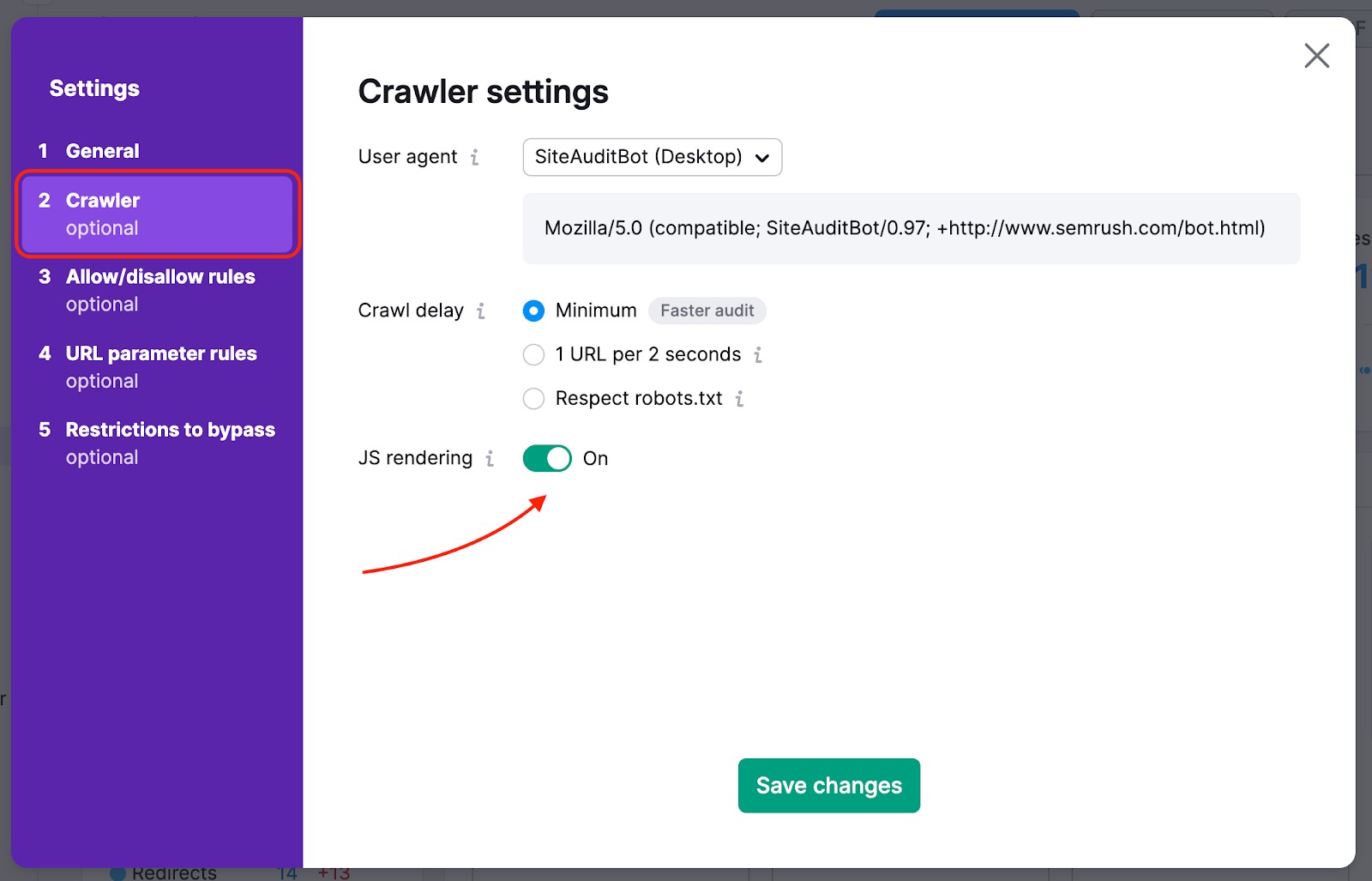
Pour éviter que nous passions à côté des pages les plus importantes de votre site Web lors de notre exploration, vous pouvez modifier votre source d’exploration en passant de « site Web » à « sitemap ». De cette manière, les robots d’exploration n’omettront aucune page, même celles qui sont difficiles à trouver naturellement sur le site Web lors de l’audit.
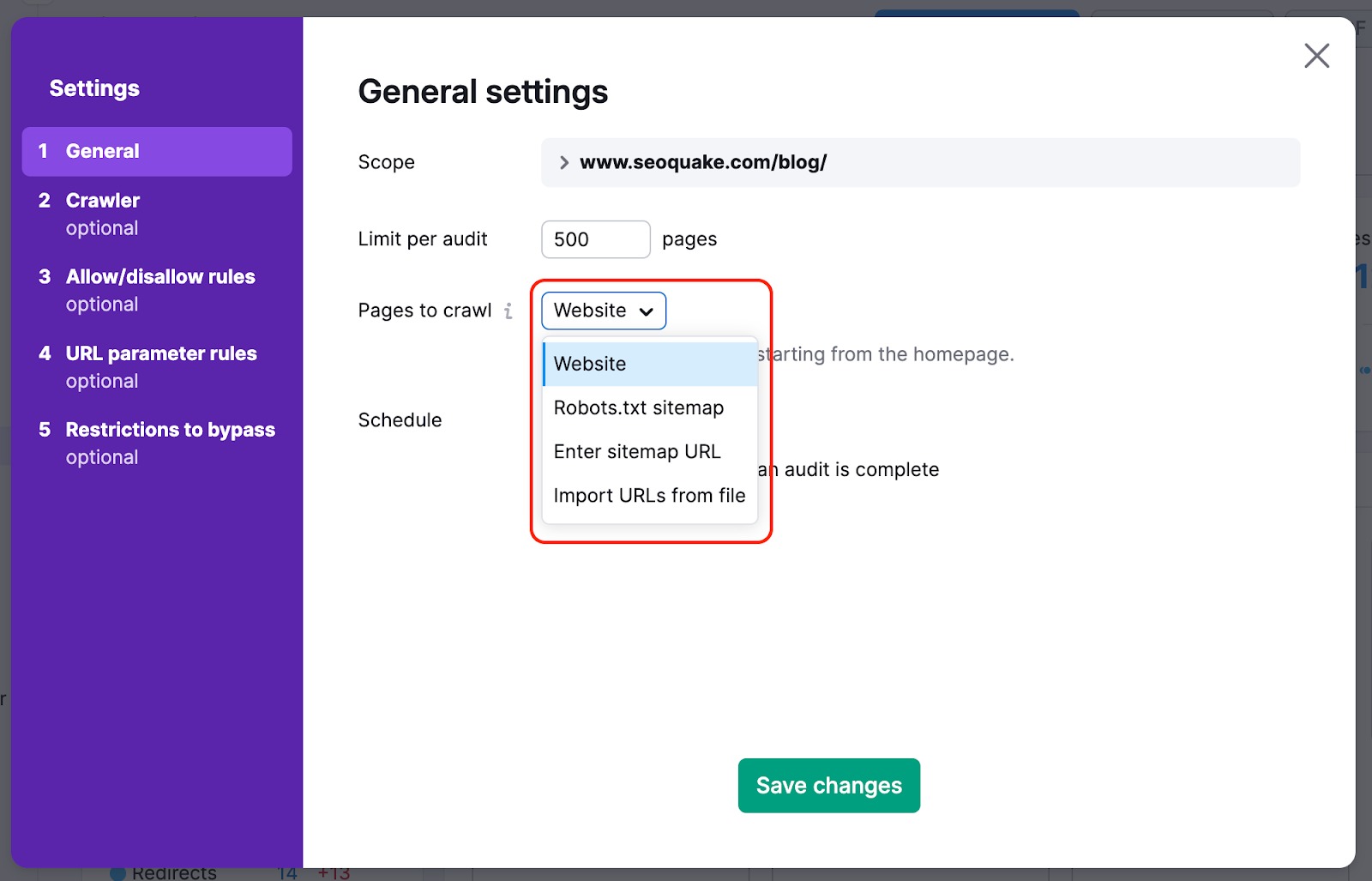
Nous pouvons également explorer le code HTML d’une page contenant des éléments JS et examiner les paramètres de vos fichiers JS et CSS lors des contrôles de performance.
Votre site Web bloque peut-être le SemrushBot dans votre fichier robots.txt. Vous pouvez faire passer le user agent de SemrushBot à GoogleBot, ce qui permettra probablement à votre site Web d’être exploré par le robot d’exploration de Google. Pour ce faire, cliquez sur l’icône d’engrenage dans votre projet et sélectionnez « User-agent ».
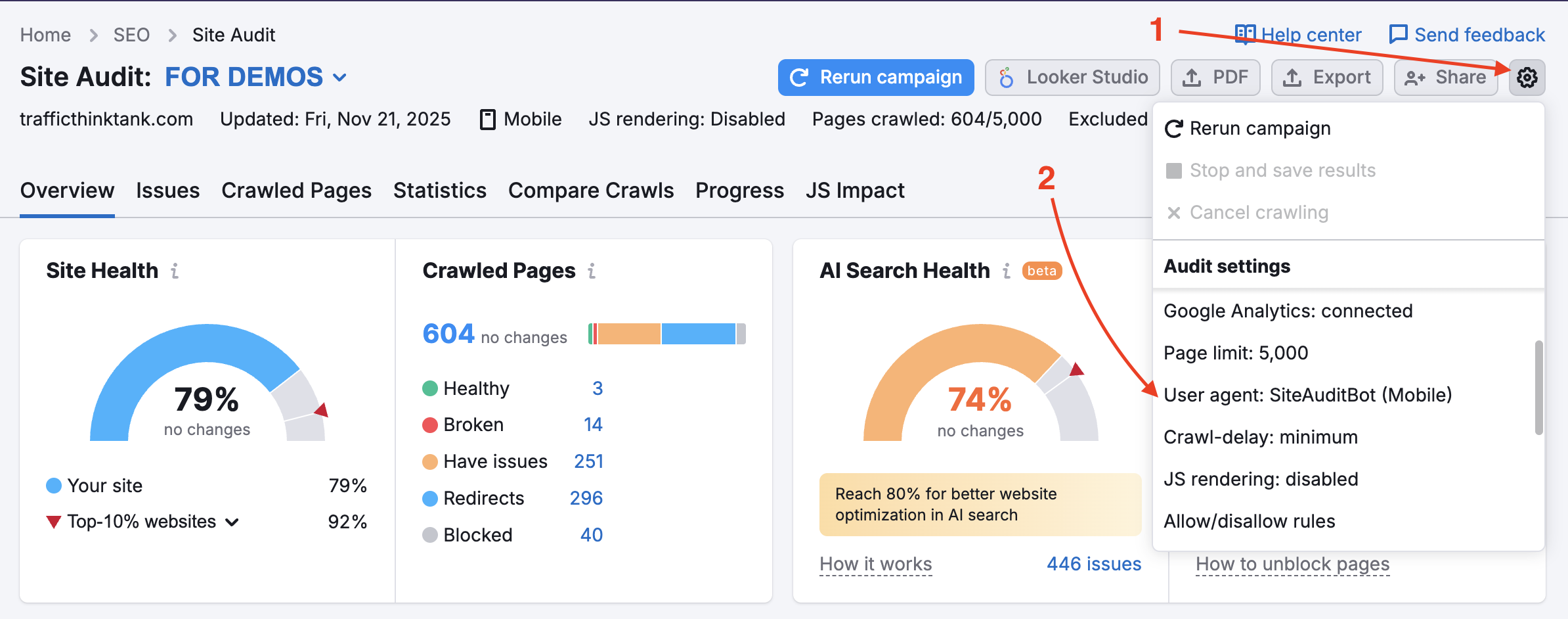
Si cette option est utilisée, les vérifications d’exploration ne seront pas déclenchées pour les ressources internes et les pages bloquées. N’oubliez pas que pour utiliser cette option, nous devons vérifier la propriété du site.
Cela peut être utile pour les sites en cours de maintenance ou lorsque le propriétaire du site ne veut pas modifier son fichier robots.txt.
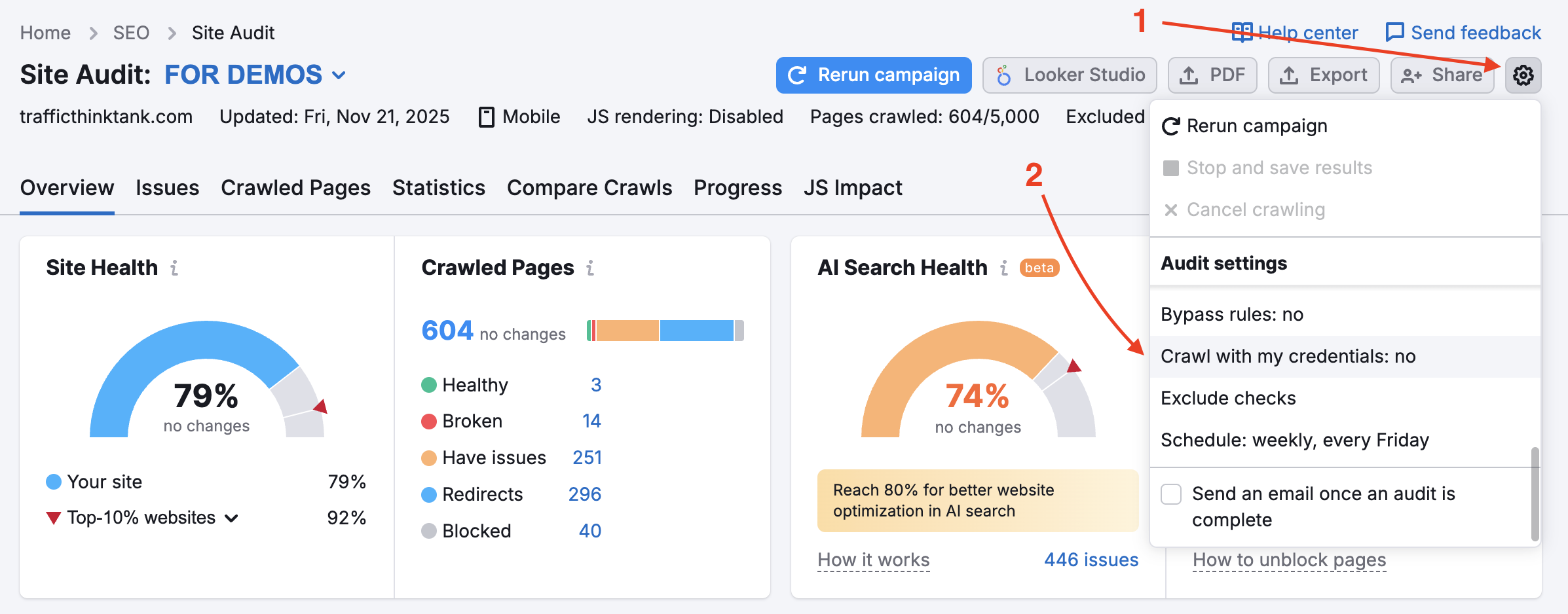
Pour auditer les zones de votre site Web protégées par un mot de passe, saisissez vos identifiants dans l’option « Exploration avec vous identifiants » sous l’icône des paramètres.
Ceci est vivement recommandé pour les sites encore en développement ou ceux qui sont privés et entièrement protégés par un mot de passe.
« Les paramètres de votre robot d’exploration ont été modifiés depuis votre précédent audit. Cela pourrait affecter vos résultats d’audit actuels et le nombre de problèmes détectés. »
Ce message apparaît dans Audit de site après avoir mis à jour les paramètres et relancé l’audit. Il n’indique pas un problème, mais que si les résultats de l’exploration ont changés, cala en est probablement la raison.
Consultez notre article de blog, Problèmes SEO courants et résolution.