Lorsque vous créez votre premier dossier dans Semrush, le domaine indiqué est automatiquement configuré dans Audit de site et l’outil s’exécute immédiatement. Une fois la première analyse terminée, vous pouvez consulter les résultats en accédant à l’outil Audit de site depuis le menu de gauche ou depuis la page d’accueil.
Pour tous les dossiers créés par la suite, vous devrez configurer manuellement Audit de site. Pour ce faire, créez un nouveau dossier dans Audit de site et suivez les instructions pour configurer et lancer votre campagne d’audit.
Si vous rencontrez des problèmes pour exécuter votre Audit de site, veuillez consulter la section Dépannage d’Audit de site pour obtenir de l’aide.
Paramètres généraux
Le premier onglet de l’assistant de configuration s’intitule Paramètres généraux. Vous pouvez soit lancer immédiatement un audit de votre site avec nos paramètres par défaut en cliquant sur « Commencer l’audit », soit personnaliser les paramètres. Pas d’inquétude, vous pouvez toujours modifier vos paramètres et relancer votre audit pour explorer une zone plus spécifique de votre site après la configuration initiale.
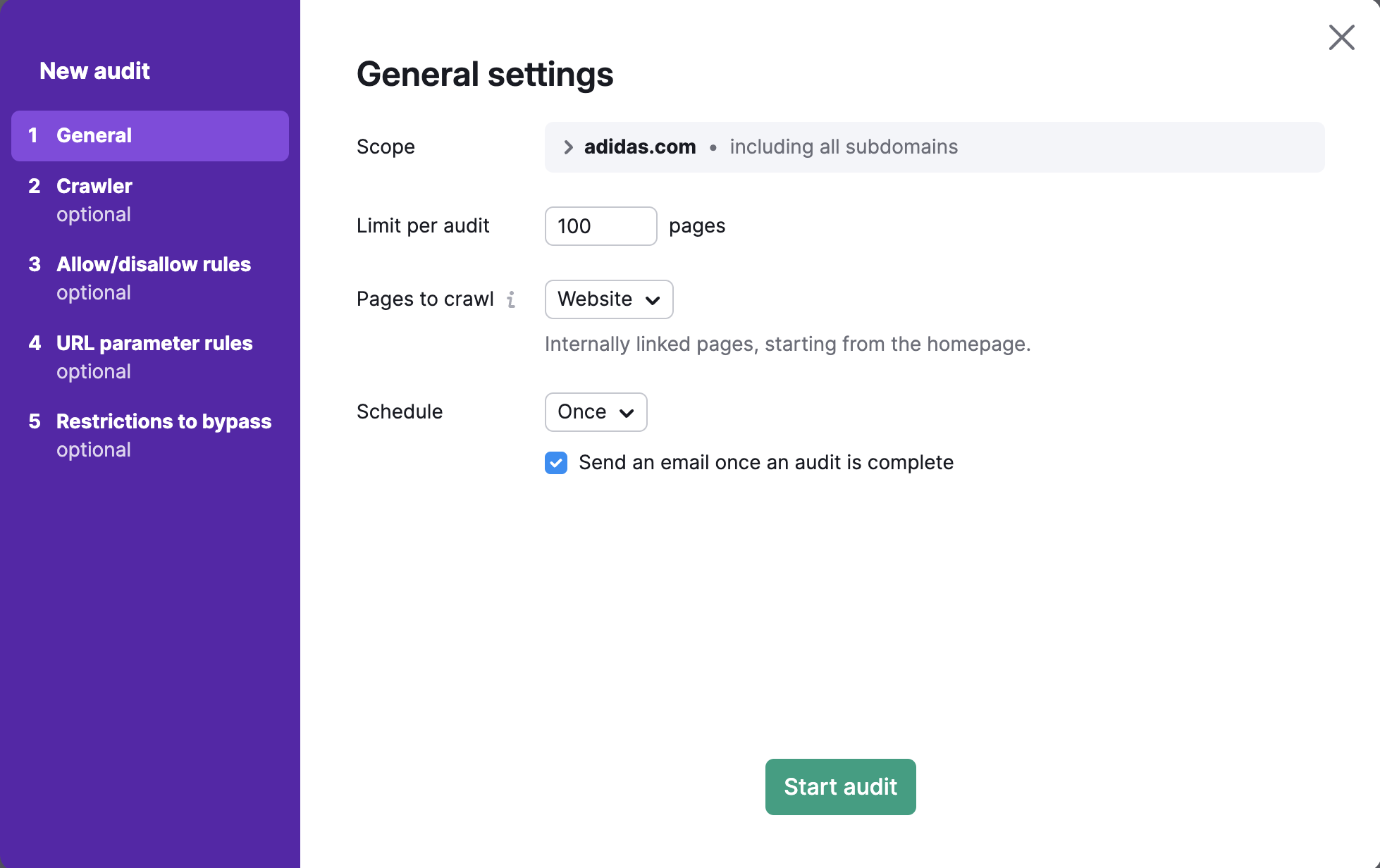
Portée de l’exploration
Pour explorer un domaine, un sous-domaine ou un sous-dossier spécifique, saisissez-le dans le champ « Portée ». Si vous saisissez un domaine dans ce champ, une case à cocher vous permettra d’explorer tous les sous-domaines de votre domaine.
Par défaut, l’outil analyse le domaine racine, qui inclut tous les sous-domaines et sous-dossiers de votre site. Dans les paramètres d’Audit de site, vous pouvez spécifier votre sous-domaine ou votre sous-dossier comme portée d’exploration et décocher « Explorer tous les sous-domaines » si vous ne souhaitez pas que les autres sous-domaines soient explorés.
Par exemple, si vous voulez auditer uniquement le blog de votre site Web, vous pouvez définir la portée d’exploration sur blog.semrush.com ou semrush.com/blog/ en fonction de s’il est implémenté en tant que sous-domaine ou sous-dossier.
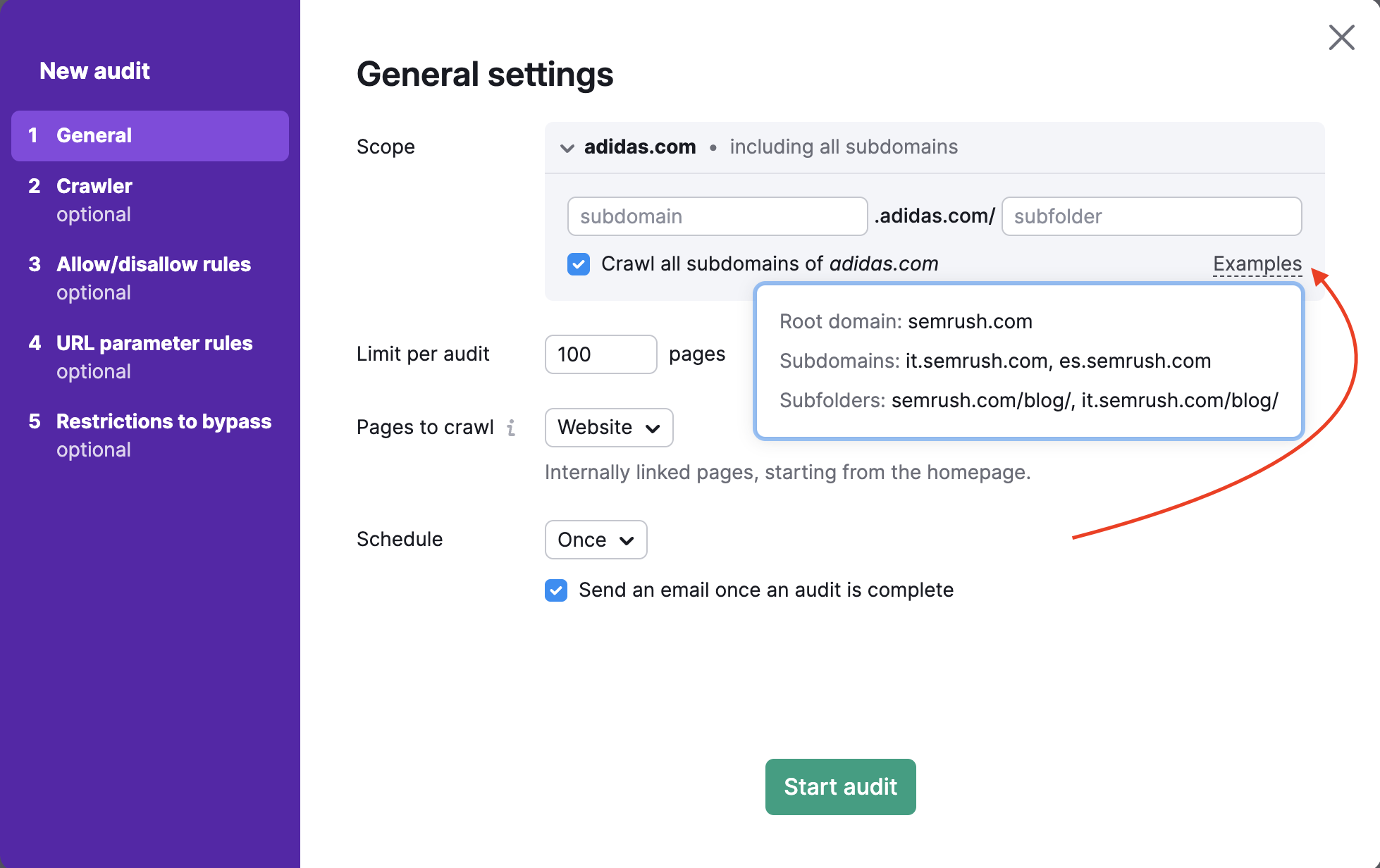
Limite de pages par audit
Sélectionnez ensuite combien de pages vous souhaitez explorer par audit. Choisissez ce nombre judicieusement, en fonction de votre forfait et de la fréquence à laquelle vous prévoyez de réauditer votre site Web.
- Les utilisateurs de la boîte à outils SEO Pro peuvent explorer jusqu’à 100 000 pages par mois et 20 000 pages par audit.
- Les utilisateurs de la boîte à outils SEO Guru peuvent explorer jusqu’à 300 000 pages par mois et 20 000 pages par audit.
- Les utilisateurs de la boîte à outils SEO Business peuvent explorer jusqu’à 1 million de pages par mois et 100 000 pages par audit
Pages à explorer
Le paramètre « Pages à explorer » détermine la façon dont le robot d’Audit de site explore votre site et trouve les pages à auditer. En plus de définir la source d’exploration, vous pouvez définir des masques et des paramètres à inclure ou à exclure de l’audit dans les étapes 3 et 4 de la configuration.
Il existe quatre options pour définir les pages à explorer : site Web, sitemap robots.txt, sitemap par son URL et liste d’URL.
1. L’exploration à partir du site Web permet d’explorer votre site comme le GoogleBot, en utilisant un algorithme de parcours en largeur et en naviguant à travers les liens présents dans le code de votre page, en commençant par la page d’accueil.
Si vous souhaitez explorer les pages les plus importantes d’un site Web, l’exploration à partir du sitemap plutôt qu’à partir du site Web permettra à l’audit d’explorer les pages les plus importantes plutôt que les plus accessibles à partir de la page d’accueil.
2. L’exploration à partir du sitemap robots.txt signifie que nous ne parcourons que les URL trouvées dans le sitemap dont le lien figure dans le fichier robots.txt.
3. L’exploration à partir du sitemap via son URL est la même qu’à partir du sitemap robots.txt, mais cette option vous permet de saisir directement l’URL de votre sitemap.
Étant donné que les moteurs de recherche utilisent les sitemaps pour comprendre quelles pages ils doivent explorer, veillez à toujours garder votre sitemap aussi à jour que possible et l’utiliser comme source d’exploration avec notre outil pour obtenir un audit précis.
Remarque : Audit de site ne peut utiliser qu’une seule URL de sitemap comme source d’exploration à la fois, donc si votre site Web compte plusieurs sitemaps, choisissez l’option suivante (importer des URL à partir d’un fichier).
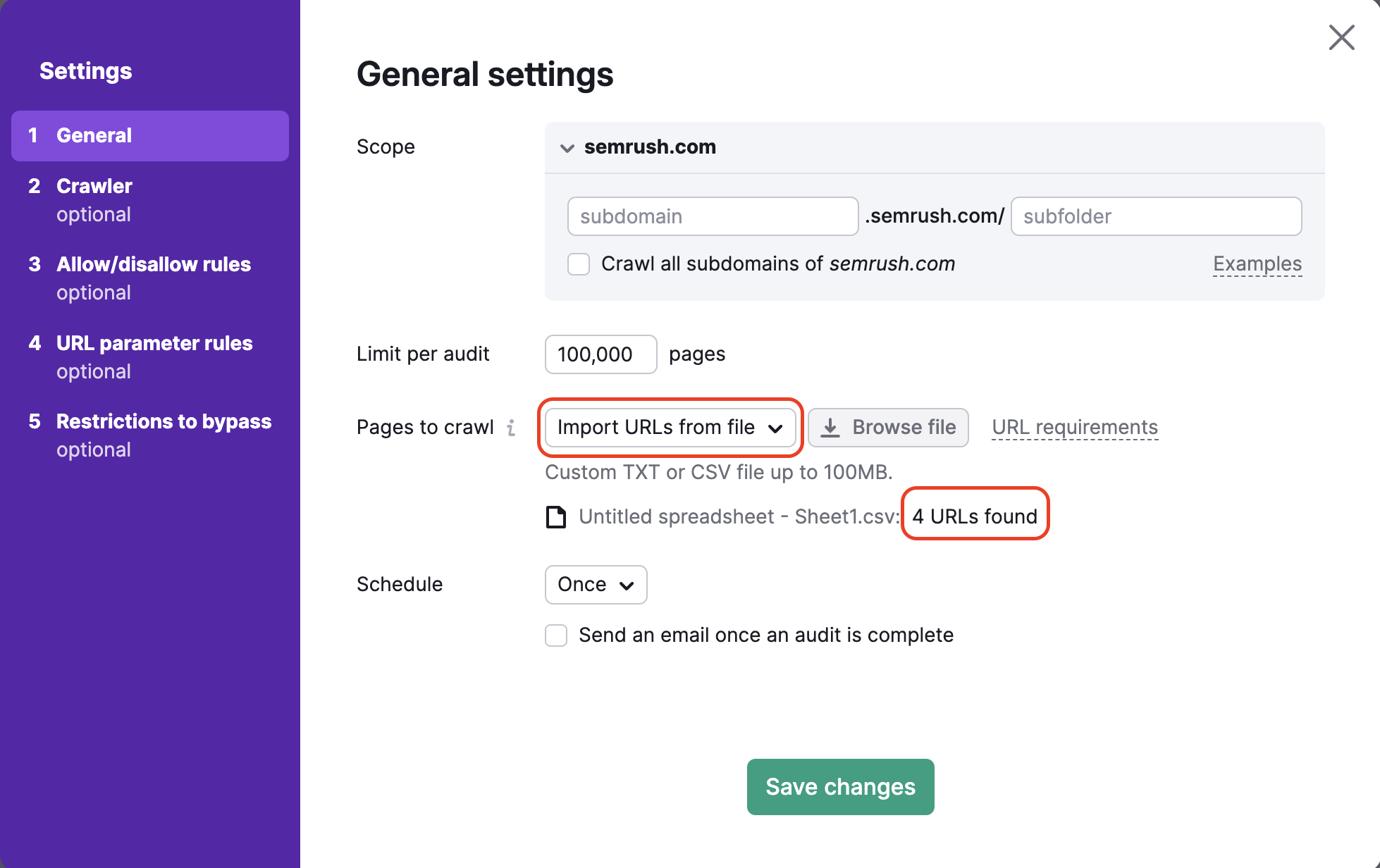
4. L’exploration à partir d’un fichier d’URL vous permet d’auditer un ensemble de pages très spécifiques sur un site Web. Assurez-vous que votre fichier est correctement formaté en .csv ou .txt avec une URL par ligne, et importez-le directement sur Semrush depuis votre ordinateur.
Cette méthode est utile pour analyser des pages spécifiques et préserver votre budget d’exploration. Si vous avez apporté des modifications à seulement un petit nombre de pages sur votre site que vous souhaitez les analyser, vous pouvez utiliser cette méthode pour exécuter un audit spécifique et ne pas gaspiller de budget d’exploration.
Après avoir importé votre fichier, l’assistant vous indiquera combien d’URL ont été détectées afin que vous puissiez vérifier que l’importation a bien fonctionné avant de lancer l’audit.
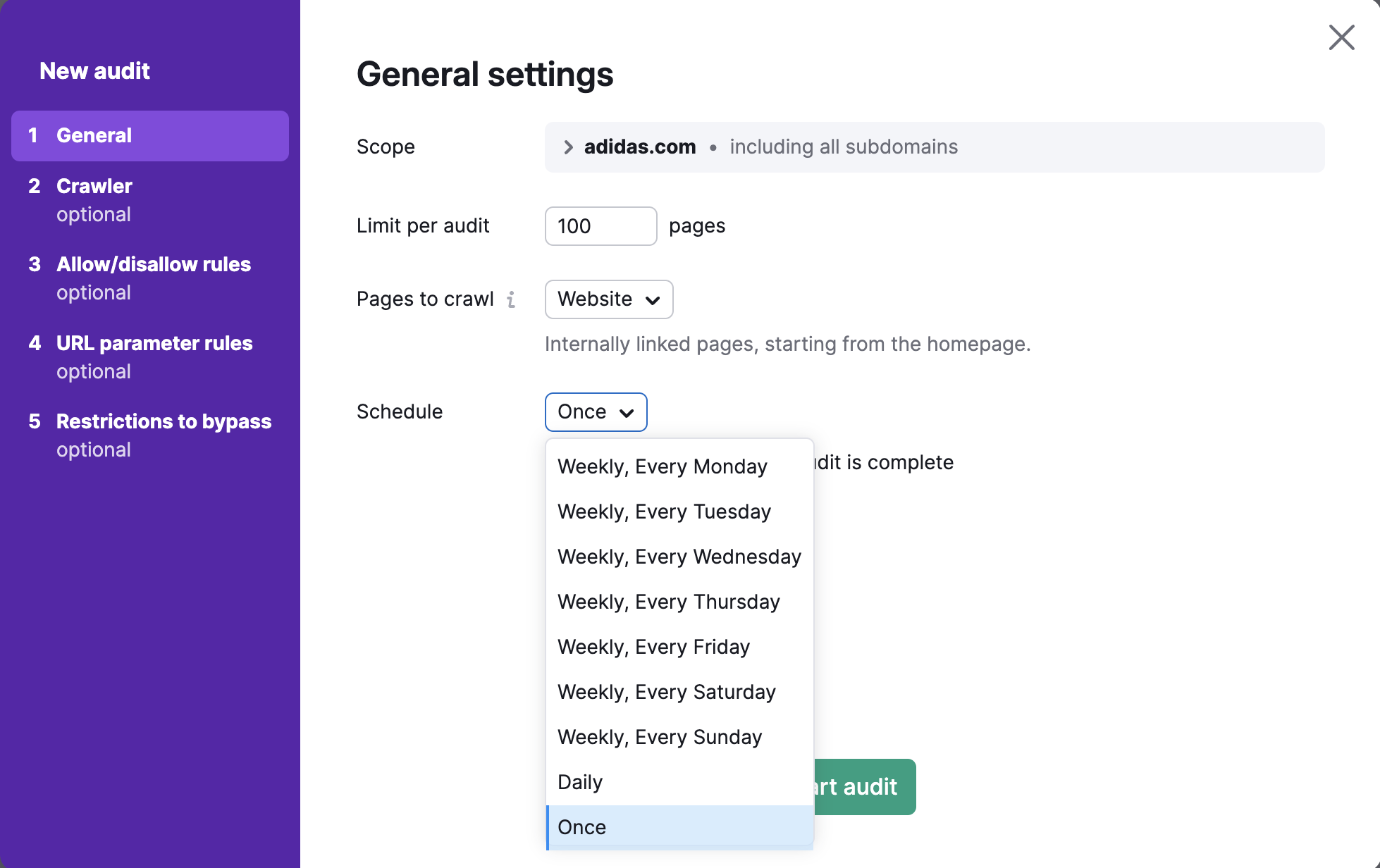
Programmation
Enfin, sélectionnez la fréquence d’audit automatique de votre site parmi les options suivantes :
- chaque semaine (le jour de votre choix) ;
- chaque jour ;
- une seule fois.
Vous pourrez toujours relancer l’audit à votre convenance.
Après avoir indiqué tous les paramètres souhaités, cliquez sur « Commencer l’audit ».
Configuration avancée
Remarque : les étapes suivantes de la configuration sont avancées et facultatives.
Paramètres du robot d’exploration
C’est ici que vous pouvez choisir l’agent utilisateur (user agent) à utiliser pour explorer votre site. Tout d’abord, définissez l’agent utilisateur de votre audit en choisissant entre la version pour mobile ou ordinateur du SiteAuditBot ou du GoogleBot. Vous pouvez également choisir l’agent utilisateur OpenAI-Search, qui vérifie si votre site Web est exploré par le nouveau robot de recherche.
Par défaut, nous analysons votre site avec notre robot d’exploration mobile qui permet d’auditer votre site Web de la même manière que le robot d’exploration mobile de Google. Vous pouvez changer et passer au robot d’exploration Semrush Desktop Crawler à tout moment.
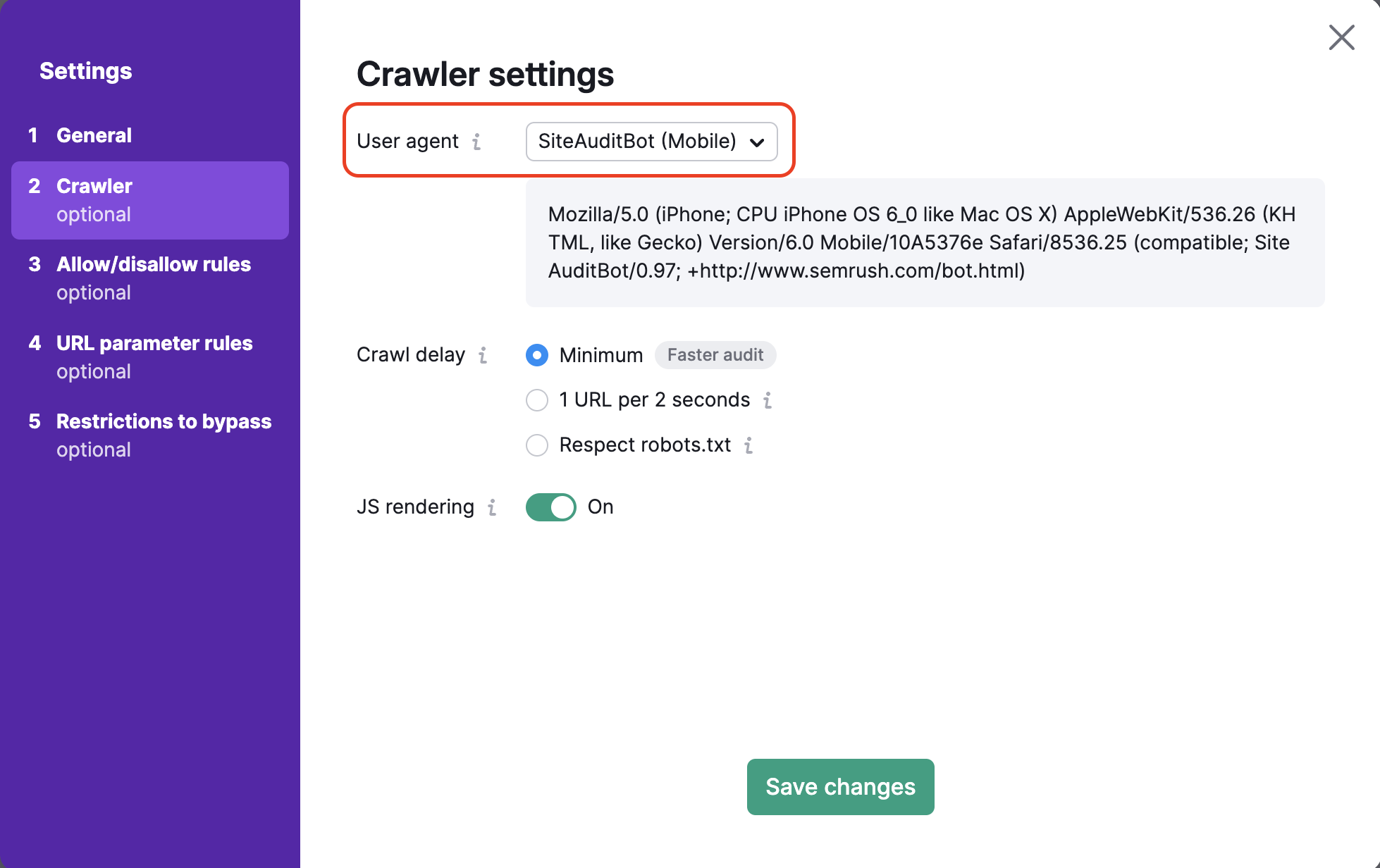
Lorsque vous modifiez l’agent utilisateur, vous verrez également le code dans la boîte de dialogue ci-dessous changer. Il s’agit du code de l’agent utilisateur qui peut être utilisé dans une commande URL client si vous voulez tester l’agent utilisateur vous-même.
Options du délai d’exploration
Vous pouvez définir le délai d’exploration sur trois options différentes : Délai minimum entre les pages, Respecter le fichier robots.txt et 1 URL toutes les 2 secondes.
Avec l’option « Délai minimum entre les pages », le robot explorera votre site Web à sa vitesse normale. Par défaut, le SiteAuditBot attendra environ une seconde avant de commencer à explorer une autre page.
Si vous avez un fichier robots.txt sur votre site et que vous y avez spécifié un délai d’exploration, vous pouvez sélectionner l’option « Respecter le fichier robots.txt » afin que le robot d’exploration d’Audit de site respecte le délai indiqué dans ce fichier.
Voici un exemple de délai d’exploration indiqué dans un fichier robots.txt :
Crawl-delay: 20
Si notre robot d’exploration ralentit votre site Web et que le fichier robots.txt ne contient pas de directive de délai d’exploration, vous pouvez demander à Semrush d’explorer 1 URL toutes les 2 secondes. Cela peut entrainer une durée d’audit plus longue, mais cela causera moins de problèmes de vitesse potentiels pour les utilisateurs réels sur votre site Web au cours de l’audit.
Exploration JavaScript
Si vous utilisez JavaScript sur votre site, vous pouvez activer le rendu JavaScript dans les paramètres de votre campagne Audit de site. Le rendu JavaScript permet à notre robot d’exploration d’exécuter les fichiers JavaScript et de voir le même contenu que vos visiteurs. Vous obtiendrez ainsi des résultats d’exploration plus précis (très proches de ceux de Googlebot) et un meilleur aperçu de la santé de votre site.
Si le rendu JavaScript est désactivé, Audit de site n’analyse que le code HTML de votre site. L’exploration du code HTML est plus rapide et ne ralentit pas votre site Web, mais les résultats de l’audit sont moins précis.

Veuillez noter que cette fonction n’est disponible qu’avec les forfaits Guru et Business de la boîte à outils SEO.
Règles d’autorisation et d’interdiction
Pour explorer des sous-dossiers ou bloquer certains sous-dossiers d’un site Web, suivez l’étape de configuration d’Audit de site Autoriser/interdire les URL. Cette étape permet également d’auditer plusieurs sous-dossiers à la fois.
Inclure tout ce qui se trouve dans l’URL après le domaine de premier niveau dans la zone de texte en dessous. Par exemple, si vous voulez explorer le sous-dossier http://www.exemple.fr/chaussures/hommes/, vous devez saisir « /chaussures/hommes/ » dans l’encadré « Autoriser » sur la gauche.
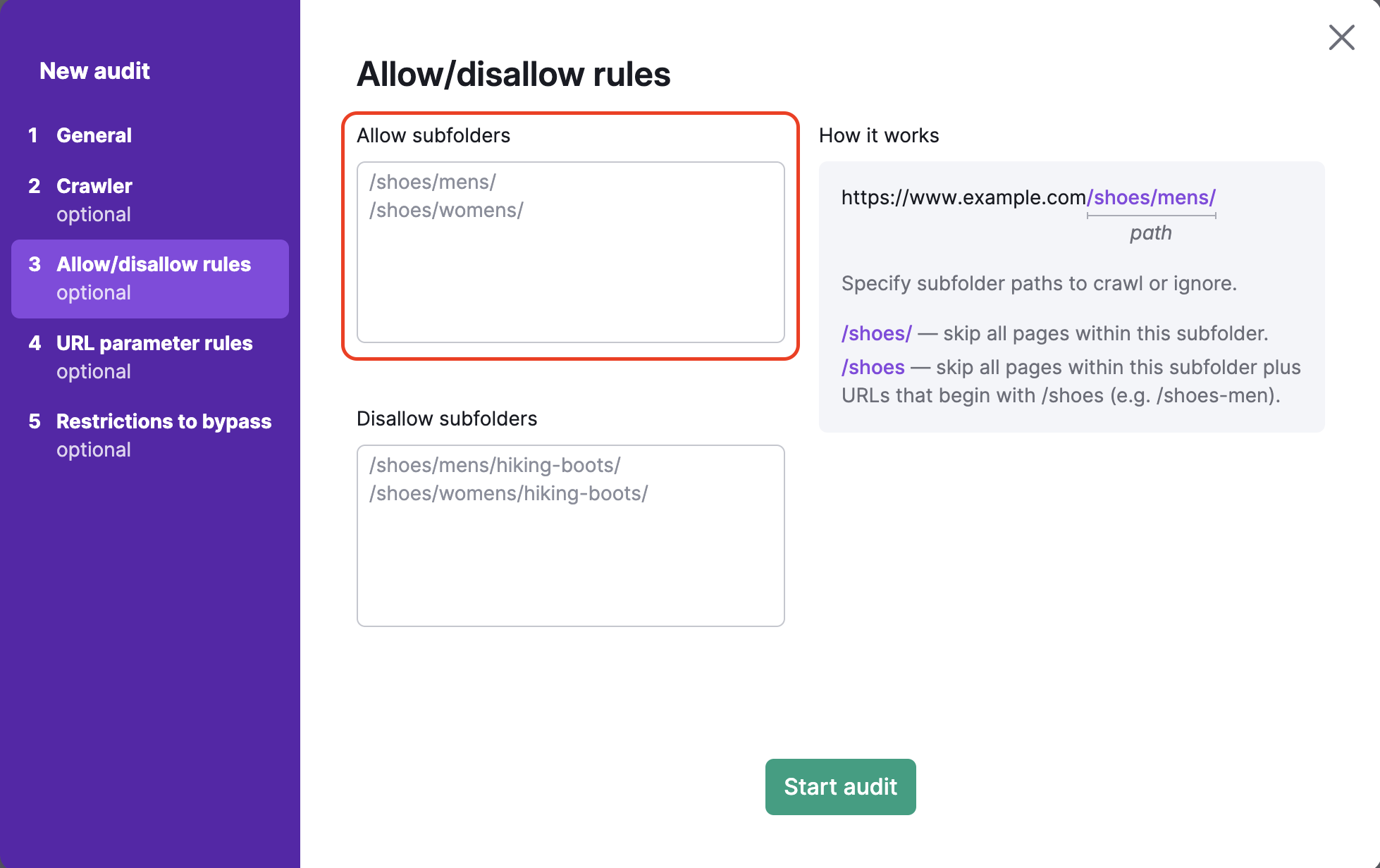
Pour empêcher l’exploration de sous-dossiers spécifiques, vous devriez saisir le chemin de ce sous-dossier dans l’encadré « Interdire ». Par exemple, pour explorer la catégorie « chaussures pour hommes » tout en évitant la sous-catégorie « chaussures de randonnée » (https://exemple.com/chaussures/hommes/chaussures-de-randonnée), vous devez saisir « /chaussures/hommes/chaussures-de-randonnée » dans le champ des sous-dossiers interdits.
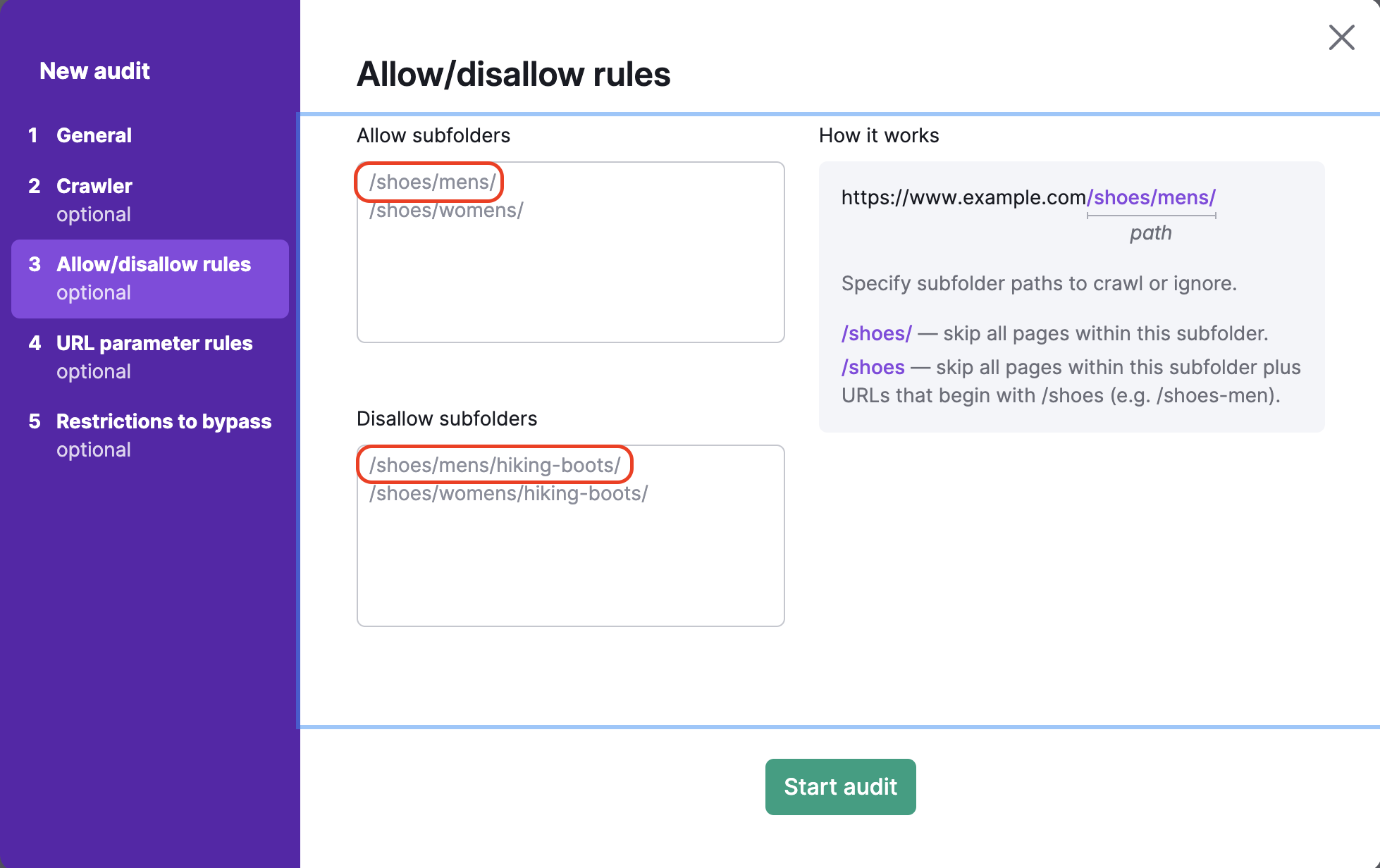
Si vous oubliez de saisir la barre oblique / à la fin de l’URL dans le champ des sous-dossiers interdits (par ex. : /chaussures), Semrush ignorera toutes les pages du sous-dossier /chaussures ainsi que toutes les URL commençant par « /chaussures » (comme www.exemple.com/chaussures-homme).
Règles sur les paramètres d’URL
Les paramètres d’URL (également chaînes de requête) sont des éléments d’une URL qui ne s’inscrivent pas dans la structure hiérarchique du chemin. À la place, ils sont ajoutés à la fin de l’URL et donnent des instructions logiques au navigateur Web.
Les paramètres d’URL sont toujours composés d’un ? suivi du nom du paramètre (page, utm_medium, etc) et =.
Par exemple, « ?page=3 » est un simple paramètre d’URL qui pourrait indiquer la 3e page de défilement sur une seule URL.
La 4e étape de la configuration d’Audit de site vous permet de spécifier les paramètres d’URL utilisés par votre site Web afin de les supprimer des URL lors de l’exploration. Cela permet à Semrush d’éviter d’explorer deux fois la même page lors de votre audit. En effet, si un bot voit deux URL, une avec un paramètre et une sans, il peut explorer les deux pages et gaspiller votre budget d’exploration.
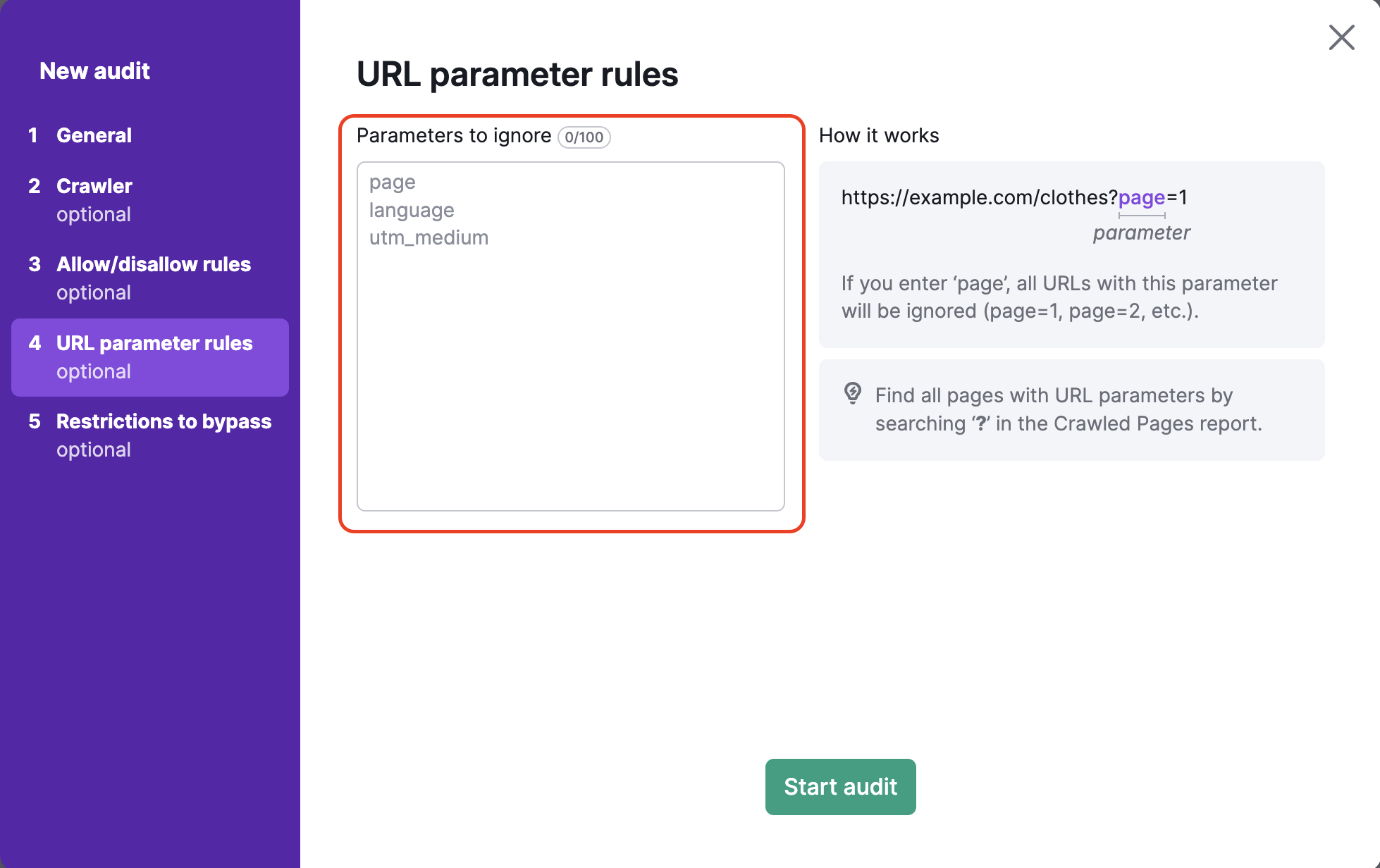
Par exemple, si vous ajoutez « page » dans cet encadré, toutes les URL qui incluent « page » dans l’extension de l’URL seront ignorées. Il s’agira d’URL avec des valeurs telles que ?page=1, ?page=2, etc. Ainsi la même page ne sera pas explorée deux fois (par exemple, « /chaussures » et « /chaussures/?page=1 » seront considérées comme une seule URL).
Les paramètres d’URL sont généralement utilisés pour gérer les pages, les langues et les sous-catégories. Ces types de paramètres sont utiles pour les sites Web proposant une grande quantité de produits ou d’informations. Un autre type courant de paramètre d’URL est l’UTM, qui est utilisé pour le suivi des clics et du trafic provenant des campagnes marketing.
Si vous avez déjà configuré une campagne d’Audit de site et souhaitez modifier vos paramètres, vous pouvez le faire en utilisant l’icône Paramètres :
Vous utiliserez les mêmes indications que ci-dessus en sélectionnant les options « Masques » et « Paramètres supprimés ».
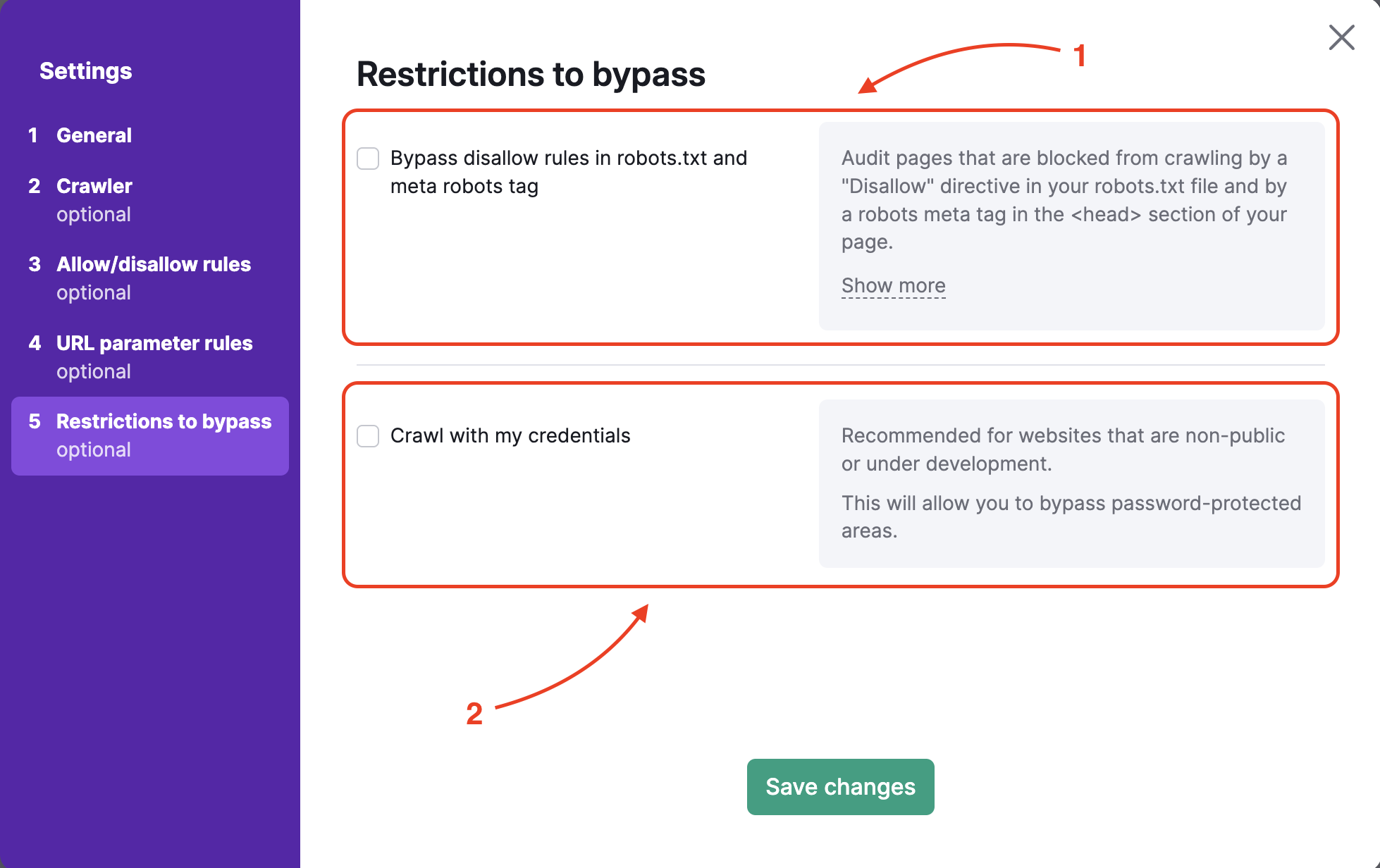
Restrictions à contourner
Pour auditer un site Web en pré-production ou protégé par une authentification d’accès standard, l’étape 5 propose deux options :
- ignorer la directive disallow dans le robots.txt et la méta balise robots ;
- explorer à l’aide de vos identifiants pour accéder aux zones protégées par mot de passe.
Si vous souhaitez contourner les directives disallow du fichier robots.txt ou la balise meta,
vous devrez importer le fichier .txt fourni par Semrush dans le dossier principal de votre site Web.Vous pouvez importer ce fichier de la même façon que pour la vérification GSC, directement dans le dossier principal de votre site Web. Ce processus permet de vérifier que vous êtes bien propriétaire du site Web et nous permet de l’explorer.
Une fois le fichier importé, vous pouvez lancer Audit de site et consulter les résultats.
Pour explorer avec vos identifiants, il vous suffit de saisir le nom d’utilisateur et le mot de passe que vous utilisez pour accéder à la partie cachée de votre site Web. Notre robot utilisera ensuite vos identifiants de connexion pour accéder aux zones cachées et vous fournir les résultats de l’audit.
Dépannage
Si une boîte de dialogue indiquant que « l’audit du domaine a échoué » s’affiche, vérifiez que notre robot d’exploration d’Audit de site n’est pas bloqué par votre serveur. Pour garantir une exploration correcte, veuillez suivre les étapes de dépannage d’Audit de site afin de mettre notre robot sur liste blanche.
Vous pouvez également télécharger le fichier journal généré lorsque l’exploration échoue et le fournir à votre webmaster afin qu’il puisse analyser la situation et essayer de trouver la cause du problème.
Associer Google Analytics et Audit de site
Après avoir terminé les étapes de l’assistant de configuration, vous pourrez associer votre compte Google Analytics afin d’inclure les problèmes liés à vos pages les plus consultées.
Si un problème persiste lors de l’exécution d’Audit de site, reportez-vous à l’article Résolution des problèmes d’Audit de site.