Pourquoi seules quelques pages de mon site Web sont-elles explorées ?
Si vous remarquez que seules 4 à 6 pages de votre site Web sont explorées (votre page d’accueil, les URL des sitemaps et robots.txt), c’est que notre robot n’a vraisemblablement trouvé aucun lien interne sortant depuis votre page d’accueil. Voyons quelques causes possibles.
Il se peut que votre page d’accueil ne comporte pas de liens internes sortants ou que les liens soient incorporés dans du JavaScript. Notre robot n’analyse le contenu JavaScript que si vous disposez du forfait Guru ou Business de la boîte à outils SEO. Par conséquent, si vous ne possédez aucun des forfaits Guru ou Business et que votre page d’accueil contient des liens vers d’autres sections de votre site au sein d’éléments JavaScript, nous ne pourrons ni les détecter ni les explorer.
Bien que l’exploration du JavaScript ne soit disponible qu’avec les forfaits Guru et Business, nous pouvons tout de même explorer le code HTML des pages contenant des éléments JavaScript. De plus, nos vérifications de performance peuvent analyser les paramètres de vos fichiers JavaScript et CSS, quel que soit votre forfait.
Dans un cas comme dans l’autre, il existe un moyen de faire que notre robot explore vos pages. Modifiez l’option « Pages à explorer » dans les paramètres de votre campagne, en remplaçant « Site Web » par « Sitemap » ou « Importer des URL à partir d’un fichier ».
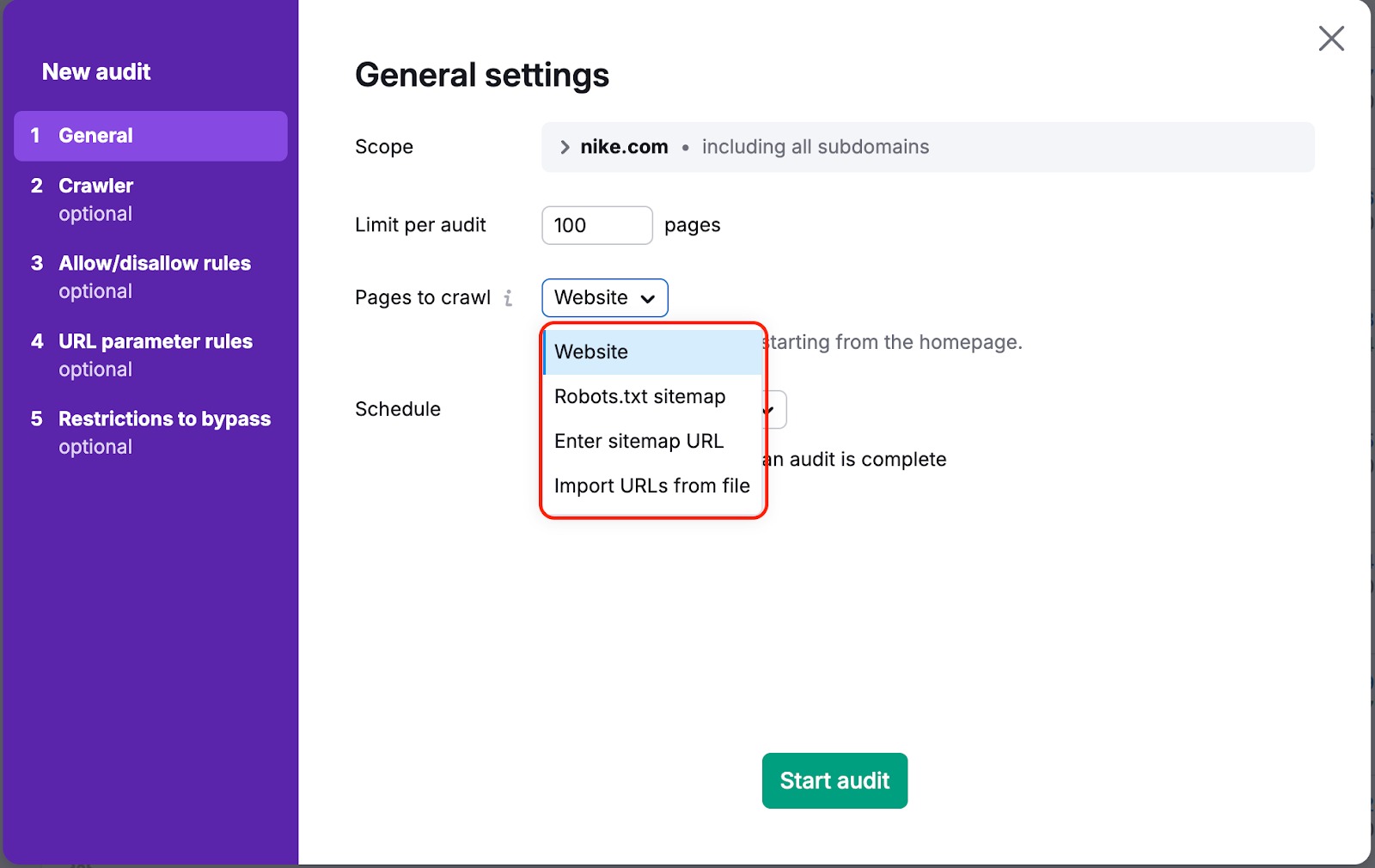
Par défaut, la source est définie sur « Site Web ». Nous explorons donc votre site Web à l’aide d’un algorithme de parcours en largeur, en commençant par la page d’accueil et en suivant les liens contenus dans son code.
Si vous choisissez l’une des autres options, nous explorerons les liens qui se trouvent dans le plan du site ou dans un fichier que vous transférez.
Notre robot d’exploration a pu être bloqué sur certaines pages dans le fichier robots.txt du site Web ou par des balises noindex ou nofollow. Pour le vérifier, reportez-vous au rapport Pages explorées.
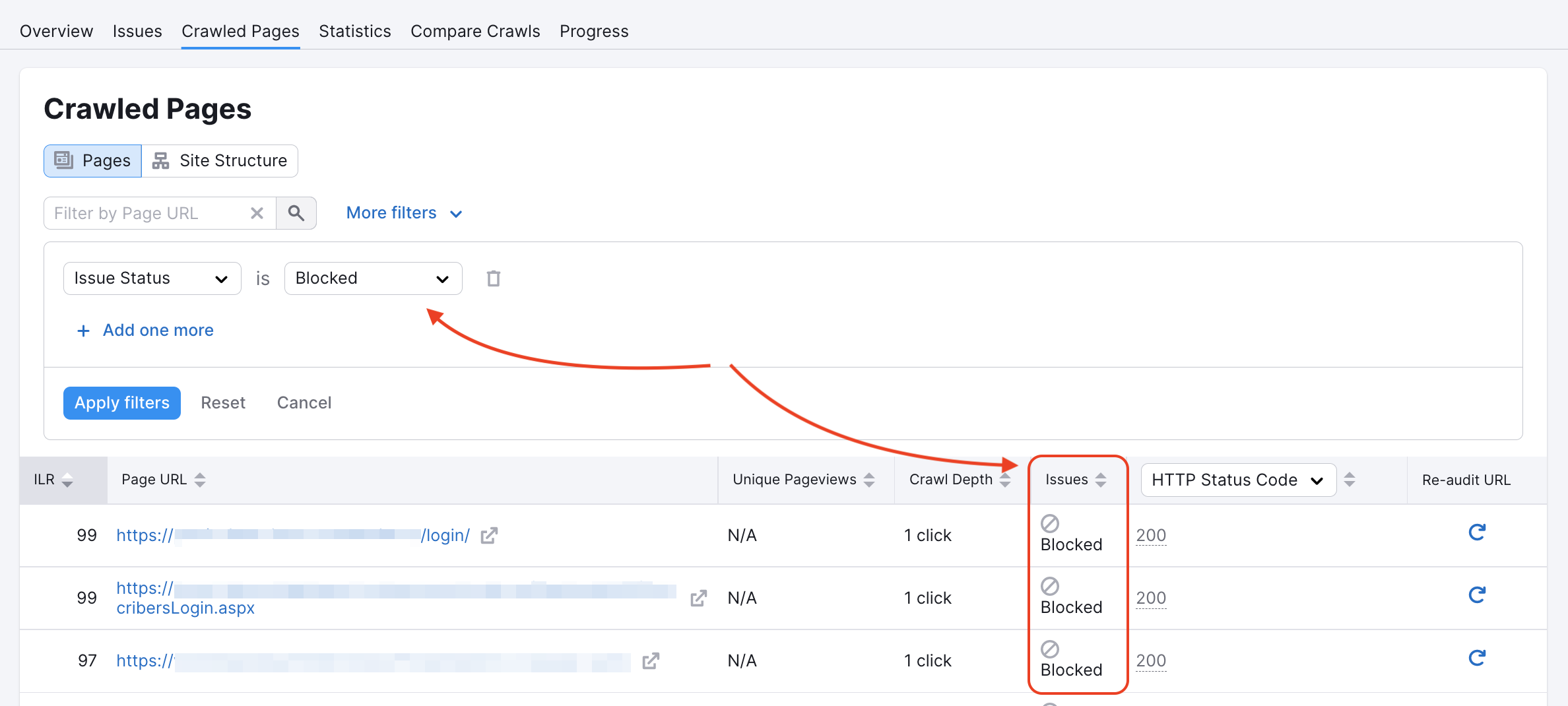
Commencez par inspecter votre fichier robots.txt à la recherche de commandes « Disallow » qui pourraient empêcher les robots d’exploration comme le nôtre d’accéder à votre site Web.
Si cette commande apparaît sur la page d’accueil, nous ne pouvons pas suivre ni indexer les liens qui s’y trouvent, car notre accès est bloqué. De même, la présence d’au moins l’un des codes « nofollow » ou « none » sur une page entraînera une erreur d’indexation.
Vous trouverez plus d’informations dans notre article de dépannage concernant ces erreurs.
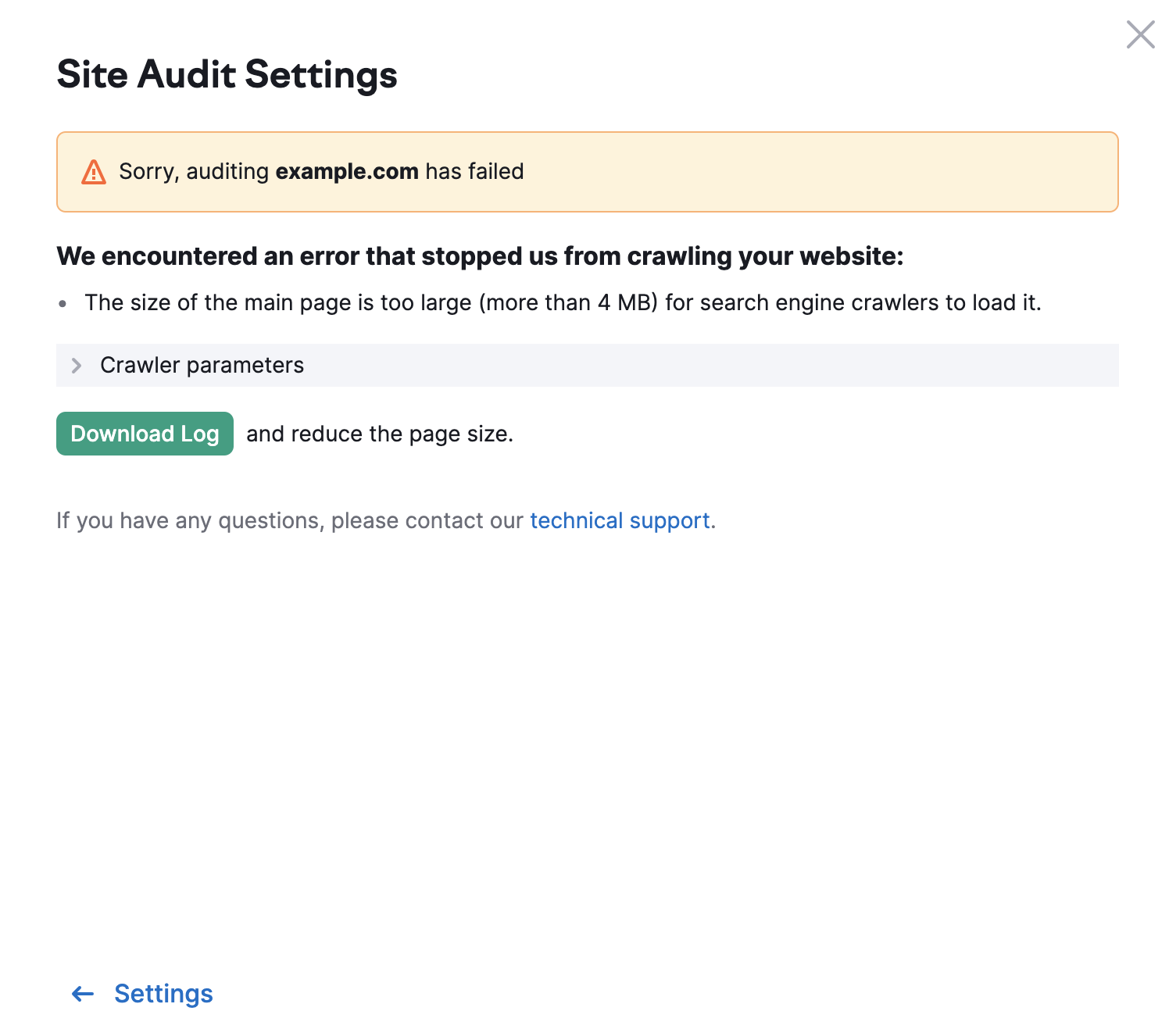
Pour les autres pages de votre site, la limite est de 2 Mo. Si le code HTML d’une page est trop volumineux, vous verrez apparaître le message d’erreur suivant :
