Comment Semrush transforme les données de trafic en renseignements pratiques
Vous vous demandez peut-être d’où proviennent les données sur le trafic que vous voyez dans notre boîte à outils Trafic et marché.
Cet article révèle les processus fondamentaux de la collecte de données brutes à la création d’informations prêtes à l’emploi visibles dans les outils.
Essentiellement, toutes les données passent par les quatre étapes clés suivantes :
- collecte des données ;
- nettoyage des données ;
- modélisation des données ;
- livraison des données.
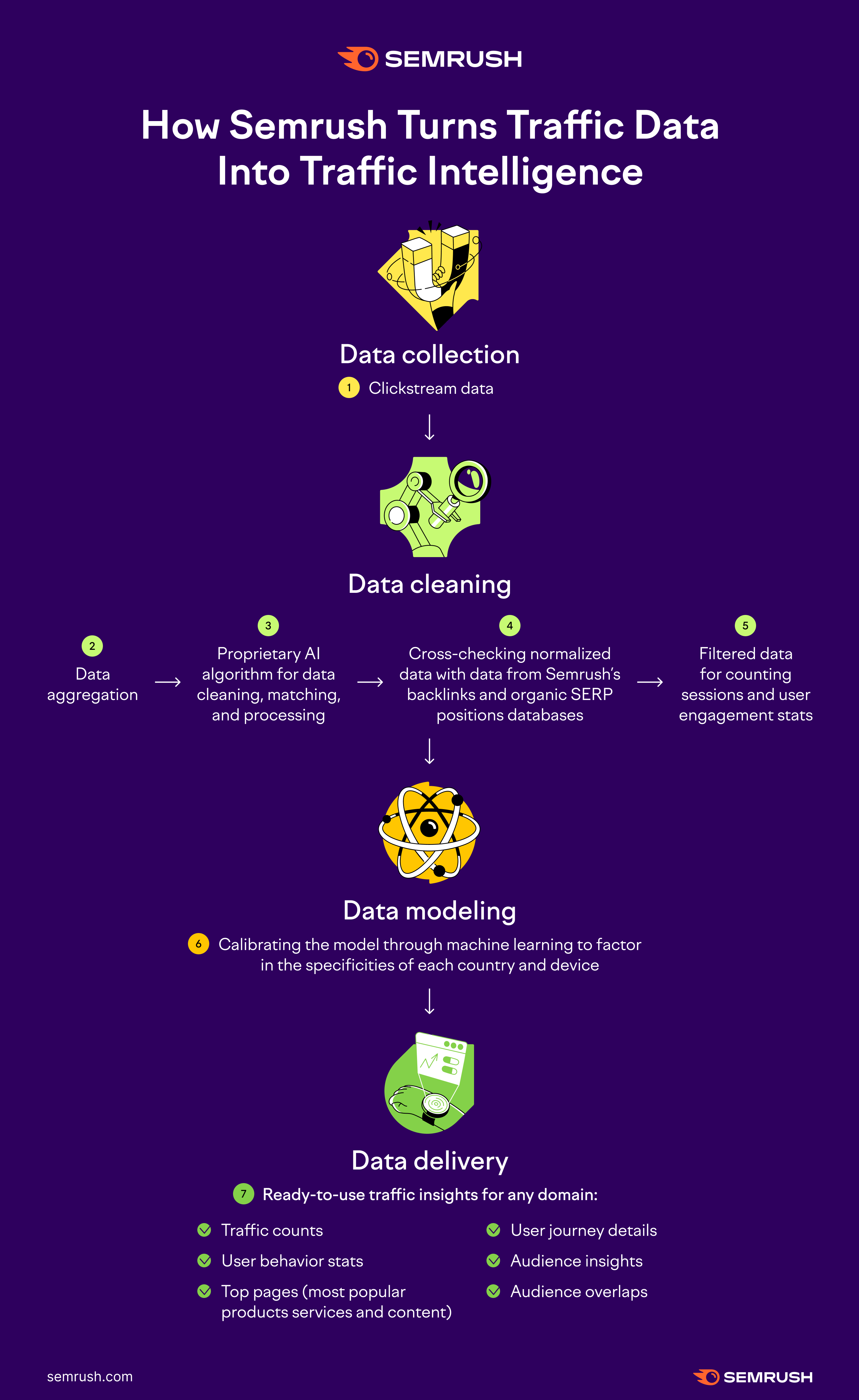
Collecte des données
Nous recevons plusieurs téraoctets de données provenant d’un panel de divers fournisseurs de données tiers chaque jour ou tous les deux jours. Ce sont les données clickstream, qui fournissent une vue agrégée des parcours en ligne de millions d’internautes réels mais anonymisés, suivant leur activité en ligne.
Les données clickstream nous permettent de déterminer les statistiques générales et les tendances en matière de comportement des utilisateurs.
Nettoyage des données
Toutes les données sont agrégées et harmonisées selon un format standard dans le système d’analyse du trafic.
En utilisant notre modèle de machine learning exclusif, nous éliminons les anomalies des données de diverses manières.
À mesure que notre IA continue d’apprendre, elle commence à identifier des motifs de la même manière qu’un cerveau humain, ce qui transforme notre modèle en un algorithme complet capable de repérer les anomalies et de mieux séparer les données douteuses des données représentatives.
Nous effectuons également une vérification croisée des données avec la base de données des backlinks de Semrush et la base de données des positions organiques dans les SERP, afin de nous assurer qu’elles correspondent aux particularités de chaque pays et appareil.
Une fois que les données ont été passées en revue par notre algorithme, nous obtenons une vision plus réaliste des sessions des utilisateurs génériques, et c’est sur la base de ce jeu de données que nous construisons nos métriques d’intéraction.
Modélisation et livraison des données
À ce stade, nous disposons d’une grande base de données dans laquelle nous stockons les données clickstream et les données propriétaires.
Avant d’alimenter notre modèle de machine learning avec ces données, elles sont soumises à une vérification supplémentaire. Nous normalisons les données en prenant en considération la popularité du domaine, ainsi que le comportement « typique » des internautes dans différents pays, groupes démographiques, appareils et secteurs industriels.
Par exemple, un internaute américain qui n’utilise le Web qu’une fois par mois aura davantage tendance à visiter Google (un domaine populaire) plutôt que le site web de la FDA (un domaine moins fréquenté). C’est pourquoi nous excluons les internautes présentant des modèles d’activité très faibles, dans le but d’obtenir des données plus précises, que ce soit pour les sites Web populaires ou moins visités.
Cela nous permet d’injecter des données plus pertinentes dans notre modèle de machine learning.
L’algorithme est soumis à un processus d’apprentissage supervisé, ce qui implique que notre technologie big data ne cesse de s’améliorer et d’apprendre au quotidien.
Données journalières et hebdomadaires sur le trafic
Semrush propose des données quotidiennes et hebdomadaires dans le tableau de bord Trafic et marché. Cette fonctionnalité améliorée s’accompagne de l’adoption d’un nouveau modèle d’IA offrant une granularité, une précision et une stabilité du trafic accrues. Alors qu’auparavant, nous traitions uniquement les données à l’échelle mensuelle, le nouveau modèle permet désormais de traiter les données journalières. Le traitement des données sur une base journalière nous permet de fournir des métriques de trafic quotidien et hebdomadaire de domaines concurrents.
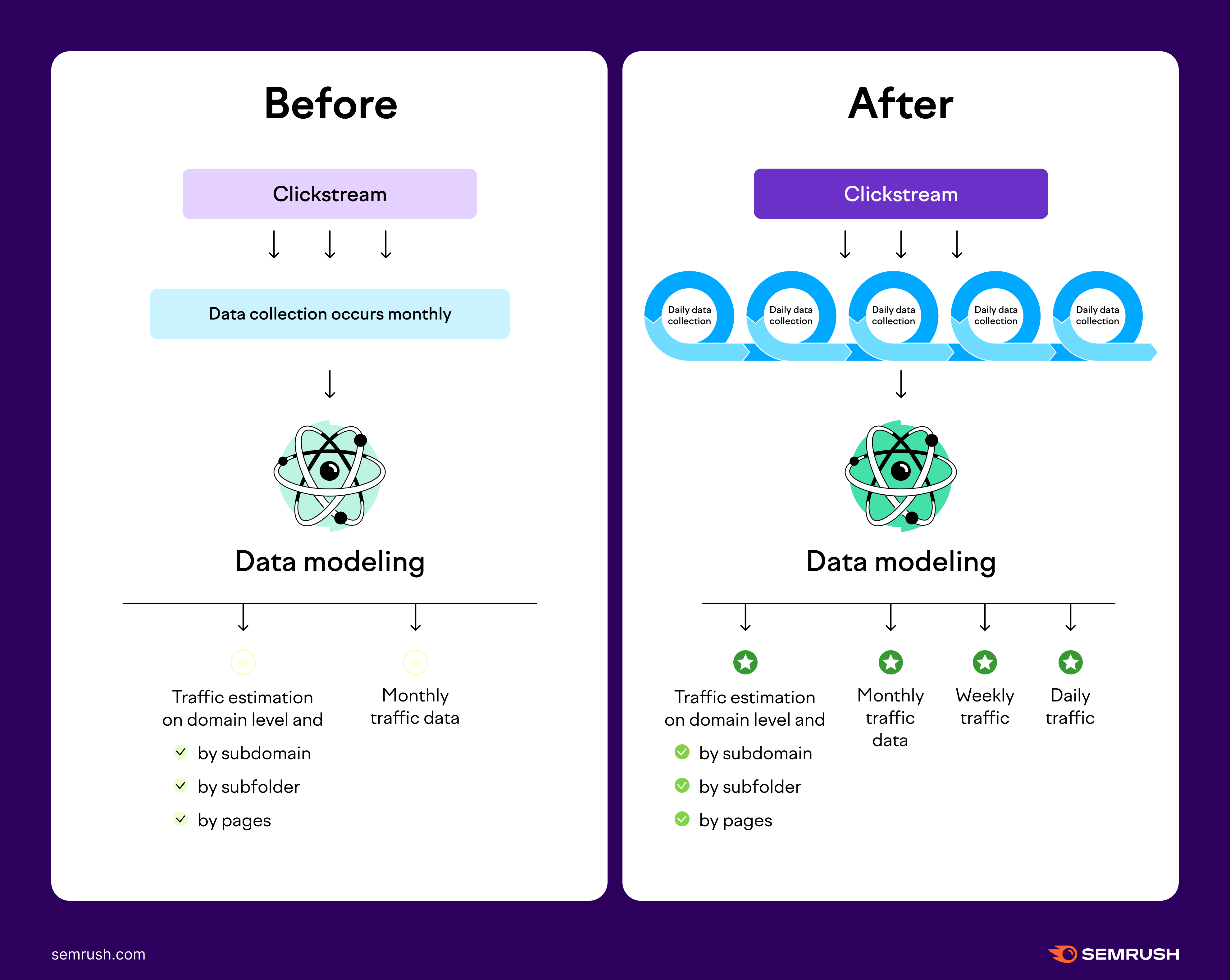
Grâce à ce modèle IA amélioré fournissant des données de meilleure qualité, nous pouvons affiner nos estimations antérieures, ce qui peut entraîner des ajustements dans les métriques.
À propos de la couverture des données de trafic de Semrush
La qualité des données est primordiale. Nous travaillons continuellement à enrichir nos outils avec de nouvelles données, tandis que nos technologies d’intelligence artificielle et de big data continuent d’apprendre et de perfectionner leurs algorithmes.
Nous avons récemment mis à jour notre modèle de traitement des données pour recueillir des données d’analyse sur le trafic, ce qui nous a permis d’augmenter notre couverture des données de trafic de 20 %.
Ci-dessous, vous pouvez découvrir en détail ce qui a changé.

*Les événements représentent le fait qu’un utilisateur a consulté une certaine page Web.
**Les sessions sont un ensemble d’actions qu’un internaute effectue sur un site Web donné pendant une période limitée. Dans Trafic et marché, nous utilisons le terme « visites » pour désigner les sessions.