
On peut supposer sans risque que Bing et Google sont organisés et fonctionnent de façon similaire.
Ainsi, si Google ne nous en dit pas beaucoup sur ses algorithmes, je suppose que poser la question à Bing permet de mieux les comprendre.
C’est donc ce que j’ai fait.
Voici la première interview d’une série de cinq que j’ai menées avec des chefs d’équipe chez Bing.
Je les publierai tous sous forme d’articles en anglais sur le Search Engine Journal et en français sur le blog de SEMrush (ainsi que les conversations complètes, non coupées, sur mon podcast « With Jason Barnard… » et sur la chaîne YouTube de Kalicube.pro).
On commence en grand avec Frédéric Dubut, responsable de programme principal chez Bing.

Toute SERP se fonde sur les (10) liens bleus
Frédéric Dubut affirme catégoriquement que le fondement de toute page de résultats sur un moteur de recherche est constitué par les « 10 liens bleus ».
Ensuite, si la requête peut être traitée directement et efficacement avec un élément riche (SERP Feature), l’algorithme incorpore le meilleur résultat dans ce format.
Si de multiples éléments riches peuvent apporter de la valeur à l’utilisateur, ils sont également ajoutés.
Voilà qui confirme ce que Gary Illyes de Google a affirmé en mai dernier à Sydney. Mais avec plus de vigueur.
Si vous ne l’avez pas encore fait, avant de continuer, n’hésitez pas à lire cette explication détaillée sur le darwinisme dans les résultats de recherche selon Illyes.
En voici une explication ultra-simplifiée :
Les fonctionnalités SERP sont tout simplement un format supplémentaire qui vit ou meurt selon leur utilité/valeur pour l’utilisateur, telle qu’elle est évaluée par une combinaison d’algorithmes darwiniens. Nous appellerons dans la suite de cet article "classement de candidats" ces algorithmes particuliers - pour les Featured Snippets Q&A, les vidéos et les images, etc.
C’est tout. C’est aussi simple que cela.
Cet article initial sur la manière dont fonctionne le classement de Google couvrait un large domaine, mais quand j’en ai parlé à Frédéric Dubut, il a poussé les choses plus loin :
- Chaque classement de candidat (donc chaque algorithme de classement) a une équipe dédiée derrière lui.
- Il existe une équipe derrière l'algorithme de la Page Entière qui joue un rôle d’« arbitre » afin de s’assurer que la page apporte le « maximum » de valeur à l’utilisateur.
Une équipe dédiée (et un algorithme adapté) derrière chaque classement de candidat
Chaque algorithme de classement de candidats s’appuie sur le même « algorithme lien bleu » centralisé, et il utilise un système modulaire qui isole les signaux (appelez-les facteurs, si vous voulez) et leur applique différentes pondérations.
Et chaque algorithme de classement de candidats a une équipe spécialisée qui travaille sur la manière de :
- Développer des solutions en se basant sur cet algorithme centralisé pour répondre au mieux aux particularités de la fonctionnalité en question.
- Générer les meilleurs résultats possibles pour ce classement, et le présenter comme un candidat pour la SERP.
Si un classement de candidat fournit un résultat qui représente une amélioration par rapport aux 10 liens bleus originaires, il obtient une place dans la SERP !
Algorithme du featured snippet Q&A
Si l’on prend comme exemple un featured snippet, être précis, actualisé et faire autorité est plus important qu’avoir tout un tas de liens.
Les featured snippets (Q&A dans le monde de Bing) sont également un excellent exemple de réponse à une requête, mais plus efficace pour l’utilisateur, ce qui constitue une amélioration évidente et immédiate par rapport au lien bleu.
Fait intéressant, l’équipe Q&A est située dans le bureau à côté de l’équipe des liens bleus.

Le troisième article de cette série sera d'ailleurs consacré à mon interview avec Ali Alvi, qui dirige l’équipe Q&A. C’est le plus long de la série, mais il est extrêmement intéressant.
Un détail qui reste gravé dans mon esprit est le fait qu’il dirige l’équipe qui génère les descriptions pour les résultats liens bleus.
Et quand vous mettez ça en relation avec l’explication apportée par Fabrice Canel (dans le deuxième article à paraître de cette série) sur les annotations qu’il ajoute quand il indexe / stocke les pages explorées par le bing bot, alors tout s’éclaire et s’imbrique harmonieusement.
Algorithme multimédia
Les vidéos et les images sont d’autres exemples faciles à saisir d’éléments riches qui apportent à l’utilisateur plus de valeur que les liens bleus, pour certaines intentions : c’est évidemment le cas de toute requête contenant le mot « image » ou « vidéo », mais aussi à peu près toutes les requêtes autour des stars de la musique ou des artistes visuels.
On notera cependant avec intérêt que les classements candidats vidéo et image sont gérés par la même équipe : Multimédia.
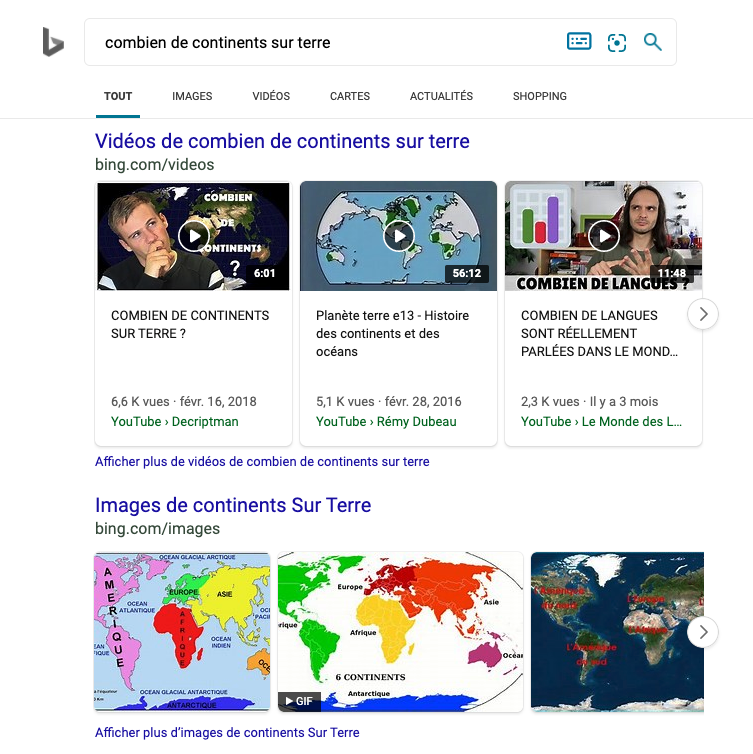 Les images et vidéos chez Bing
Les images et vidéos chez Bing
Le 4ème article de cette série contient l’interview effectuée avec Meenaz Merchant, qui dirige l’équipe Multimédia : vous y trouverez des informations vraiment intéressantes, notamment sur l’importance de l’autorité et de la confiance dans le classement de candidats multimédias.
Annonces Bing : « Encore un autre classement de candidats »
Une fois que quelqu’un vous a expliqué l’idée derrière ces classements de candidats en concurrence pour une place sur la SERP, la question naturelle qui nous vient est : et les annonces, alors ?
Elles sont tout simplement, en effet, un autre classement de candidats.
Si l’annonce la plus pertinente apporte de la valeur à l’utilisateur, elle a alors un « droit » à de l’espace sur la SERP.
Et le principe clé pour l’annonce réside dans le fait que Bing veut satisfaire ses utilisateurs. Afin de retenir son audience, Bing doit s’assurer qu’il affiche des annonces dont le contenu va satisfaire la requête des utilisateurs.
Les annonces sont donc simplement un autre classement candidat qui étend les options sur la SERP avec une équipe derrière lui.
Néanmoins, comme pour le reste, l’algorithme de la Page entière prend la décision finale. Il s’agit de trouver cet équilibre délicat entre générer des revenus pour l’entreprise et servir l’utilisateur. En cas de déséquilibre important, les choses risqueraient de se détériorer très rapidement.
Ainsi, Google possède probablement plus de 90% des parts de marché. Mais trop d’annonces qui ne servent pas peuvent provoquer un désastre, même à ce degré de domination.
Cela dit, les annonces n’en restent pas moins un cas spécial. Peu importe ce que disent Google et Bing, il est évident qu’ils conservent un biais commercial intéressé. Mais au niveau macro, j’aurais tendance à être moins critique et à suggérer que leur survie sur le long terme dépend des algorithmes créant un équilibre raisonnable entre les liens naturels et payants.
L’idée que l’une de ces compagnies va privilégier l’argent sur le court terme au détriment du long terme n’est pas rationnelle d'un point de vue commercial.
Mais plus important encore, si personne ne clique sur l’annonce, ils ne gagnent pas d’argent !
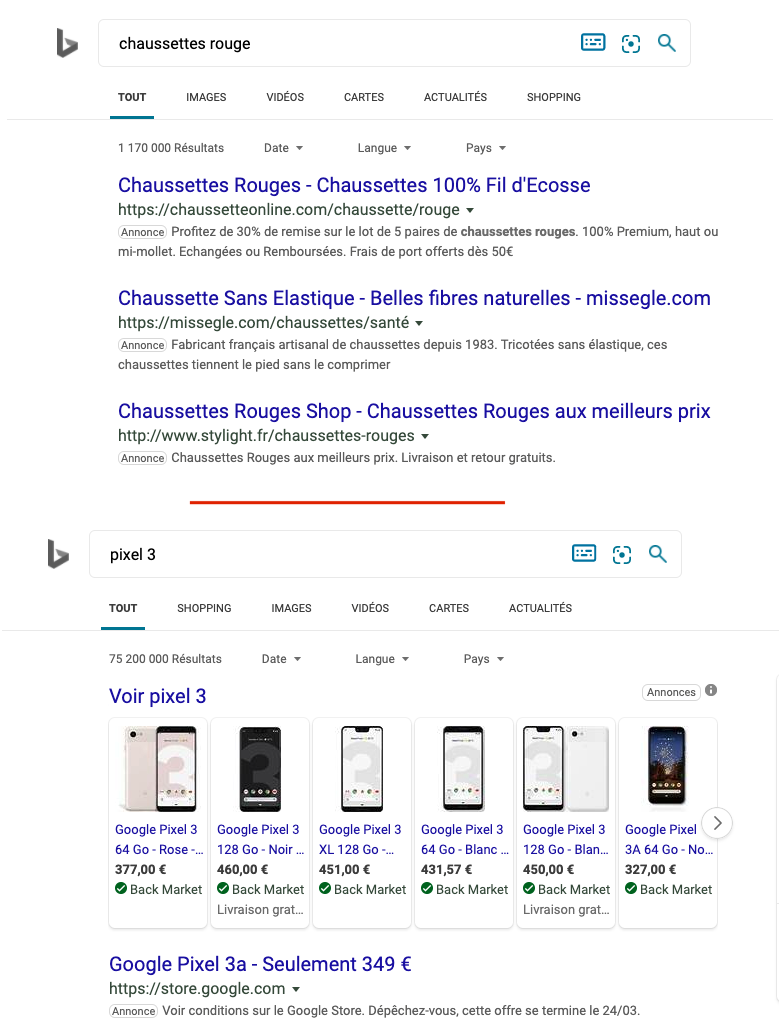 Les annonces sur Bing
Les annonces sur Bing
Vu la façon dont la SERP est présentée, nous avons donc une situation où les annonces doivent remplir le même rôle que les autres candidats qui se battent pour une place sur la SERP : donner une voie alternative ou fournir la même réponse dans un format attrayant et utile pour l’utilisateur.
Gagner de l’argent consiste donc à s’assurer que l’annonce est attrayante en tant que solution immédiate pour l’utilisateur : une alternative vraiment valable aux liens bleus ou aux résultats enrichis... Et cela dépend de la capacité des annonceurs à :
- Enchérir sur une requête où ils ont réellement une solution.
- Fournir un texte d’annonce qui soit utile et qui ait de la valeur pour l’utilisateur.
Et si nous considérons les annonces shopping comme des éléments riches / fonctionnalités SERP de la même manière que les encadrés vidéo, les featured snippets, etc., nous pouvons voir que les annonces vont évoluer selon une logique darwinienne dans les années à venir !
L’équipe de la page entière
C’est le moment qui a vraiment piqué ma curiosité durant ma conversation avec Dubut.
Le darwinisme sous-entend que tout élément riche / fonctionnalité SERP qui veut apparaître sur la SERP vit et meurt en fonction de son aptitude à convaincre l’algorithme qu’il a plus de valeur que le lien bleu.
Et c’est vrai jusqu’à un certain degré.
Chaque « classement candidat » génère la meilleure réponse possible (vidéo, image, featured snippet, People Also Ask…) et il place son « enchère », mais ce n’est pas lui qui décide si elle apparaît : c’est le rôle de l’algorithme de la page entière.
L’équipe de la page entière est un concept d’une importance phénoménale et une découverte clé !

Le 5ème article de cette série contient l’interview de Nathan Chalmers, qui dirige l’équipe de la Page entière, et il confirme que l’algorithme de la page entière gère bien ce qui s’affiche au bout du compte sur la SERP de BING.
Les SERP ne fonctionnent pas sur des principes purement darwiniens... Mais Chalmers suggère tout de même que mon concept de darwinisme dans les résultats de recherche est une très bonne façon d’envisager les choses. Mieux encore, il me dit qu’ils ont chez Bing un algorithme qui s’appelle... Darwin ?
Comme on peut s’y attendre, l’algorithme de la page entière est basé sur l’intention. Il pondère les résultats et s’assure que les éléments riches qui servent le mieux l’intention ont une bonne performance.
Pour Beyonce, par exemple, il est important d’afficher des vidéos et des news, car c’est ce que veulent les utilisateurs. Dans des cas comme celui-là, les 10 liens bleus n’ont pas beaucoup d’importance.
Voilà un exemple où l’algorithme maître / de la page entière exerce une énorme influence sur la décision concernant ce qu’il faut afficher.
Une explication simple de l’apprentissage automatique dans le(s) algorithme(s)
 Illustrations : Véronique Barnard
Illustrations : Véronique Barnard
- L’humain dit à la machine quels sont les facteurs (ou fonctionnalités, comme Nathan les appelle ?) qu’il juge importants, et lui donne des règles pour déterminer ce qui doit être considéré comme un succès ou comme un échec.
- La machine est ensuite nourrie d’un vaste nombre d’exemples d’étiquetage humain de bons et de mauvais résultats pour un éventail de différentes requêtes de recherche.
- La machine trouve alors les différentes pondérations pour les fonctionnalités qui fourniront des résultats de qualité en toute circonstance, quelle que soit la demande (même pour les nouvelles requêtes que la machine n’a encore jamais vues).
Frédéric Dubut suggère qu’une bonne façon d’aborder ce problème consiste à voir l’algorithme comme un simple modèle de mesure... Il mesure le succès et l’échec, et il s’adapte en fonction.
Mais il est important de comprendre que les humains jouent un rôle central. Les machines n’ont pas le champ libre : l’algorithme est construit par des humains qui fournissent (à travers des exemples) une définition du bon et du mauvais.
Ce sont aussi des humains qui créent et maintiennent la plateforme qui définit quelles fonctionnalités sont importantes... et lesquelles ne le sont pas.
L’apprentissage automatique équilibre simplement toutes les fonctionnalités pour satisfaire au mieux ce jugement humain.
Le cycle de l’apprentissage automatique
C’est un processus continu. Bing envoie en permanence des feedbacks aux algorithmes afin qu’ils puissent s’améliorer.
Après l’étape 3 définie ci-dessus, les juges humains évaluent et étiquettent les résultats.
Les données sont utilisées par les équipes de l’algorithme pour ajuster les fonctionnalités et les règles, puis les données étiquetées sont renvoyées dans la machine.
Le retour négatif est utilisé par la machine pour l’ajustement et l’amélioration. Le retour positif permet de consolider l’apprentissage déjà acquis.
Il semble donc que ce soit un apprentissage pour nous tous.
Les directives du juge humain de Bing
Ce qui est important, c’est que les retours des juges humains soient structurés, non pas basés uniquement sur l’intuition humaine, car il y aurait alors des variations d’un juge à l’autre et cela rendrait le retour déroutant ou contradictoire pour la machine.
La structure prend la forme d’un ensemble de directives (équivalent aux directives des évaluateurs de qualité chez Google) qui assurent la cohérence et maximalisent l’objectivité des retours données aux machines.
L’évaluation humaine des résultats est réinjectée en permanence dans les algorithmes de Bing (cf. ci-dessus), ce qui permet aux machines d’adapter et d’améliorer les pondérations de fonctionnalité et, espérons-le, d’améliorer leurs résultats au cours du temps.
Chaque équipe (Multimédia, Q&A / Featured Snippet, knowledge panels, etc.) a ses propres panels de juges humains et ses propres directives qui se concentrent sur les exigences d’un élément riche particulier.
Cela semble indiquer qu’il y aurait d’autres directives des évaluateurs chez Google, ce qui est aussi très intriguant.
Cela veut dire aussi (pour moi, du moins) que quiconque écrit ces directives exerce une influence forte et indirecte sur les pondérations relatives des facteurs de classement (les fameuses fonctionnalités).
Et que ces pondérations doivent varier significativement d’un élément riche à l’autre.
Encore une fois, l’Équipe de la page entière représente un cas intéressant : leurs juges humains et leurs directives produisent (vraisemblablement) l’impact le plus important.
 Illustrations : Véronique Barnard
Illustrations : Véronique Barnard
Les liens bleus ne vont pas disparaître de sitôt
Les éléments riches utilisent des variantes de l’algorithme central des liens bleus (de façon modulaire, si j’ai bien compris), et les 10 liens bleus forment la « SERP initiale » que tous les autres éléments ont pour objectif d’« envahir » en prouvant qu’ils fournissent plus de valeur qu’un lien bleu.
Pour récapituler (car c’est important), les SERP sont systématiquement construites à partir des 10 liens bleus. Ces derniers, à tous égards, représentent leur fondement. Ce qui veut dire qu’ils ne vont pas disparaître dans un futur proche !
L’émergence et la montée darwinienne des fonctionnalités SERP (éléments riches) en ont tué quelques-uns, mais les liens bleus ne sont pas menacés d’extinction pour autant.
La moyenne tourne probablement autour de sept liens bleus et demi par SERP.
Frédéric Dubut suggère que c’est une bonne règle générale, car l’objectif global est de faire en sorte que les SERP gardent à peu près la même taille. Mais la longueur de la SERP et le nombre de résultats sont des décisions qui sont prises en dernière instance par l’algorithme de la Page entière (nous y reviendrons plus en détail dans le cinquième article de cette série).
J’ai cherché des données fiables pour le confirmer, mais aucun des outils que j’ai utilisés jusqu’à présent n’a été en mesure d’isoler entièrement la page #1 et de fournir les données exactes pour les liens bleus en comparaison avec les éléments riches, ni pour Google ni pour Bing.
Néanmoins, j’y suis parvenu pour les requêtes de recherche exactes associées à une marque sur Google.
Ces données (sur 20 000 marques) montrent que sur Google (désolé, je n’ai pas réussi à étudier Bing), et en particulier sur les SERP de marque, il y a en moyenne 8,15 liens bleus, tandis que le nombre moyen d’éléments riches sur la gauche est 2,07.
Les éléments riches n’ont donc pas beaucoup affecté le nombre de résultats sur la page #1 des SERP, bien qu’elles se soient enrichies et aussi quelque peu allongées.
La moyenne des résultats par page est désormais légèrement supérieure à 10.
Les éléments riches tuent les liens bleus selon un rapport de un à un
La moyenne globale pour mon ensemble de données (un peu moins de 20 000 SERP de marque) est de 8,15 liens bleus et 2,07 éléments riches.

Vers la fin de l’interview, Frédéric Dubut a dit une chose éclairante et a ajouté une mise en garde intéressante pour laquelle je n’ai pas encore de données détaillées, mais qui mérite d’être étudiée.
Il a raison, le nombre de résultats reste relativement stable au fur et à mesure que des éléments riches sont ajoutés sur la partie de gauche.
Les éléments riches tuent vraiment les liens bleus... parfois
J’ai d’abord pensé, en mai dernier, quand j’écrivais l’article sur le darwinisme dans les résultats de recherche, que la présence de plus en plus importante d’éléments riches allait non seulement éliminer les liens bleus, mais réduire aussi le nombre de résultats sur la page #1.
Mon raisonnement était qu’un élément riche ne se contentait pas de prendre la place d’un lien bleu, mais (du fait de la place occupée plus grande dans le cas des encadrés Twitter, par exemple) pouvait aussi faire disparaître un lien bleu supplémentaire, et la moyenne des résultats sur la page #1 aurait alors tendance à baisser.
Faux ?
Oui.
Et non.
Deux types de requêtes
Pour la longueur de la SERP, il est utile d’examiner deux types distincts de résultats, et de prendre en compte deux règles générales.
- Pour les intentions dépourvues d’ambiguïté (dans ce cas, des noms de marque clairs), les SERP ont tendance à devenir plus riches et plus courtes. Le nombre total de résultats tend à baisser à mesure que le nombre d’éléments riches augmente. Puisque l’intention est claire, des résultats plus courts, plus riches, et plus concentrés sont ce qu’il y a de plus satisfaisant pour l’utilisateur.
- Pour les intentions ambiguës, les SERP tendent à devenir plus riches et plus longues : les éléments riches ont tendance à s’ajouter à la page des résultats et à supprimer peu de choses. Comme l’intention n’est pas claire, fournir plus de résultats avec un éventail d’intentions est ce qu’il y a de plus satisfaisant pour l’utilisateur.
Pourquoi ?
Avec les requêtes plus ambiguës, où il y a plusieurs intentions, les moteurs de recherche veulent donner des réponses plus complètes. Plus de résultats et une page plus longue sont leur manière d’offrir plus de diversité et de mieux couvrir ces intentions multiples.
Dubut et Chalmers confirment tous deux ce constat. Je suis sûr que les données viendront renforcer cette intuition : toute plateforme qui souhaite effectuer cette analyse avec moi est la bienvenue. ?
Enfin, voici un nombre intéressant pour terminer : la moyenne globale des résultats sur la Page 1 reste 10 (pour les SERP de marque, du moins) !

Voilà pour le premier de ces cinq articles consacrés au fonctionnement de l'algorithme de Bing (et par extension, de tout moteur de recherche ?) et basés sur une série d'entretiens menés par Jason Barnard tout autour du monde ! Restez attentifs, nous publierons régulièrement un nouvel épisode des BING Séries, les aventures de notre globe-trotter du SEO !
Avec Frédéric Dubut, Senior Program Manager Lead / Bing
Avec Fabrice Canel, Principal Program Manager / Bing
- Épisode 3 : Comment fonctionnent les Featured Snippets chez Bing ?
Avec Ali Alvi, Principal Program Manager - Intelligence Artificielle / Bing
- Épisode 4 : Comment fonctionnent les algorithmes vidéos et images de Bing ?
Avec Meenaz Merchant, Principal Program Manager Lead - Intelligence artificielle et recherche / Bing
- Épisode 5 : Comment fonctionne l’algorithme pleine page de Bing ?
Avec Nathan Chalmers, Program Manager - Search Relevance Team / Bing