
Qu'est-ce que robots.txt ?
Robots.txt est un fichier texte contenant des instructions destinées aux robots des moteurs de recherche : il leur indique les pages qu'ils peuvent ou ne peuvent pas explorer.
Ces instructions sont spécifiées en "autorisant" ou en "interdisant" le comportement de certains robots (ou de tous).
Voici à quoi ressemble un fichier robots.txt :
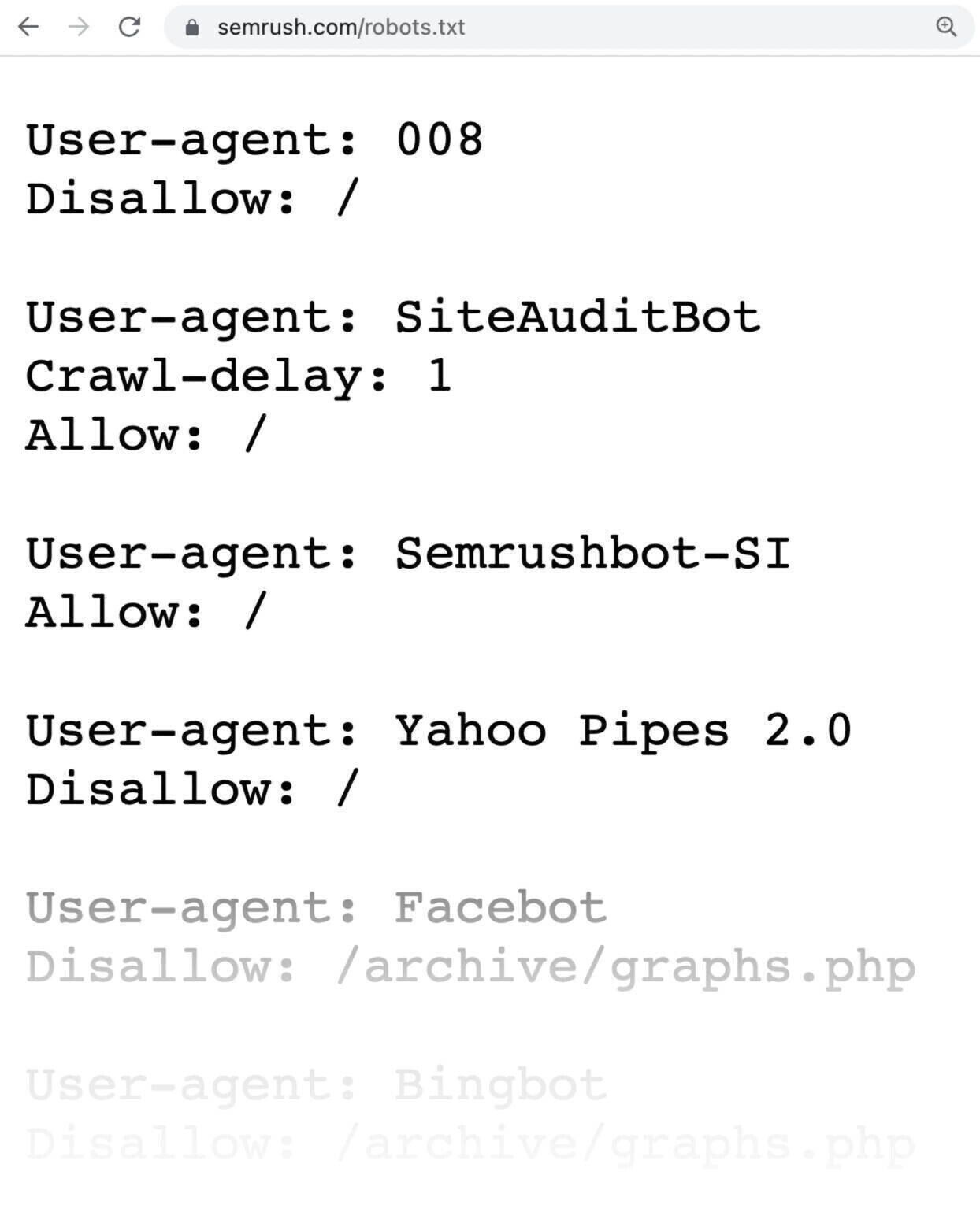
Les fichiers robots.txt peuvent sembler compliqués dans un premier temps, mais la syntaxe (langage informatique) est assez simple. Nous entrerons dans ces détails plus tard.
Dans cet article, nous allons voir :
- Pourquoi les fichiers robots.txt sont importants
- Comment fonctionnent les fichiers robots.txt
- Comment créer un fichier robots.txt
- Les meilleures pratiques pour un fichier robots.txt
Pourquoi le fichier robots.txt est-il important ?
Un fichier robots.txt permet de gérer les activités des robots d'exploration du web afin qu'ils ne surchargent pas votre site web ou n'indexent pas des pages qui ne sont pas destinées à être vues par le public.
Voici quelques raisons pour lesquelles vous pouvez utiliser un fichier robots.txt :
1. Optimiser le budget crawl
Le budget crawl est le nombre de pages que Google va explorer sur votre site à un moment donné. Ce nombre peut varier en fonction de la taille, de la santé et des backlinks de votre site.
Le budget crawl est important car si le nombre de pages dépasse le budget crawl de votre site, certaines pages de votre site ne seront pas indexées.
Et les pages qui ne sont pas indexées ne seront classées pour aucun mot clé.
Si vous bloquez les pages inutiles à l'aide de robots.txt, Googlebot (le robot d'exploration de Google) peut consacrer une plus grande partie de votre budget d'exploration aux pages importantes.
2. Bloquer les pages dupliquées et non publiques
Il n'est pas nécessaire d'autoriser les moteurs de recherche à explorer toutes les pages de votre site, car elles n'ont pas toutes besoin d'être classées.
C'est le cas, par exemple, d'un site staging (réplique identique de votre site web), des pages de résultats de recherche internes, des pages dupliquées ou des pages de connexion.
WordPress, par exemple, interdit automatiquement /wp-admin/ à tous les robots d'exploration.
Ces pages doivent exister, mais vous n'avez pas besoin qu'elles soient indexées et affichées par les moteurs de recherche. Voilà des cas où vous utiliseriez le fichier robots.txt pour bloquer ces pages aux robots d'exploration et aux bots.
3. Cacher des ressources
Parfois, vous souhaitez que Google exclue des ressources telles que les PDF, les vidéos et les images des résultats de recherche.
Vous souhaitez peut-être que ces ressources restent privées ou que Google se concentre sur un contenu plus important.
Dans ce cas, l'utilisation du fichier robots.txt est le meilleur moyen de les empêcher d'être indexées.
Comment fonctionne un fichier robots.txt ?
Les fichiers robots.txt indiquent aux bots des moteurs de recherche les URL qu'ils peuvent explorer et, surtout, celles qu'ils ne peuvent pas explorer.
Les moteurs de recherche ont deux tâches principales :
- Explorer le Web pour découvrir du contenu
- Indexer le contenu afin qu'il puisse être présenté aux internautes qui recherchent des informations
Au fur et à mesure de leur exploration, les robots des moteurs de recherche découvrent et suivent des liens. Ce processus les conduit du site A au site B puis au site C à travers des milliards de liens et de sites Web.
En arrivant sur un site, la première chose qu'un robot fera est de chercher un fichier robots.txt.
S'il en trouve un, il le lira avant de faire quoi que ce soit d'autre.
Vous vous en souvenez, un fichier robots.txt ressemble à ceci :

La syntaxe est très simple.
Vous attribuez des règles aux robots en indiquant leur agent utilisateur (le robot du moteur de recherche) suivi de directives (les règles).
Vous pouvez également utiliser le caractère générique astérisque (*) pour attribuer des directives à chaque agent utilisateur. Cela signifie que la règle s'applique à tous les bots, plutôt qu'à un bot spécifique.
Par exemple, voici à quoi ressemblerait l'instruction si vous vouliez autoriser tous les robots, à l'exception de DuckDuckGo, à explorer votre site :

Note : Si un fichier robots.txt fournit des instructions, il ne peut pas les imposer. C'est comme un code de conduite. Les bons robots (comme les robots des moteurs de recherche) suivront les règles, mais les mauvais robots (comme les robots de spam) les ignoreront.
Comment trouver un fichier Robots.txt
Le fichier robots.txt est hébergé sur votre serveur, comme tout autre fichier de votre site web.
Vous pouvez voir le fichier robots.txt de n'importe quel site Web en tapant l'URL complète de la page d'accueil, puis en ajoutant /robots.txt, comme https://semrush.com/robots.txt.

Note : Un fichier robots.txt doit toujours se trouver à la racine de votre domaine. Donc, pour le site www.exemple.com, le fichier robots.txt se situe là : www.exemple.com/robots.txt. Dans le cas contraire, les robots d'exploration supposeront que vous n'en avez pas.
Avant d'apprendre à créer un fichier robots.txt, examinons la syntaxe qu'il contient.
Syntaxe du robots.txt
Un fichier robots.txt est composé de :
- Un ou plusieurs blocs de "directives" (règles) ;
- Chacun avec un "user-agent" (robot de moteur de recherche) spécifié ;
- Et une instruction "allow" ou "disallow".
Un bloc relativement simple peut ressembler à ceci :
User-agent: Googlebot
Disallow: /not-for-google
User-agent: DuckDuckBot
Disallow: /not-for-duckduckgo
Sitemap: https://www.yourwebsite.com/sitemap.xmlLa directive User-agent
La première ligne de chaque bloc de directives est le "user-agent", qui identifie le robot d'exploration auquel il s'adresse.
Ainsi, si vous voulez dire à Googlebot de ne pas explorer votre page admin de WordPress, votre directive commencera par :
User-agent: Googlebot
Disallow: /wp-admin/N'oubliez pas que la plupart des moteurs de recherche ont plusieurs robots d'exploration. Ils utilisent différents crawlers pour leur index normal, les images, les vidéos, etc.
Les moteurs de recherche choisissent toujours le bloc de directives le plus spécifique qu'ils peuvent trouver.
Supposons que vous ayez trois ensembles de directives : un pour *, un pour Googlebot, et un pour Googlebot-Image.
Si l'agent utilisateur Googlebot-News parcourt votre site, il suivra les directives Googlebot.
En revanche, l'agent utilisateur Googlebot-Image suivra les directives plus spécifiques de Googlebot-Image.
Vous trouverez ici une liste détaillée des robots d'exploration du Web et de leurs différents agents utilisateurs.
La directive Disallow
La deuxième ligne de tout bloc de directives est la ligne "Disallow".
Vous pouvez avoir plusieurs directives "Disallow" qui spécifient les parties de votre site auxquelles le robot d'exploration ne peut pas accéder.
Une ligne "Disallow" vide signifie que vous n'interdisez rien, et qu'un robot d'exploration peut accéder à toutes les sections de votre site.
Par exemple, si vous souhaitez autoriser tous les moteurs de recherche à explorer l'ensemble de votre site, votre bloc ressemblera à ceci :
User-agent: *
Allow: /Par contre, si vous vouliez empêcher tous les moteurs de recherche de parcourir votre site, votre bloc ressemblera à ceci :
User-agent: *
Disallow: /Les directives "Allow" et "Disallow" ne sont pas sensibles à la casse, c'est donc vous qui décidez de les mettre en majuscules ou non.
Cependant, les valeurs contenues dans chaque directive le sont.
Par exemple, /photo/ n'est pas la même chose que /Photo/.
Néanmoins, vous trouverez souvent les directives "Allow" et "Disallow" en majuscules, car cela rend le fichier plus facile à lire pour les humains.
La directive Allow
La directive "Allow" permet aux moteurs de recherche d'explorer un sous-répertoire ou une page spécifique, même dans un répertoire autrement interdit.
Par exemple, si vous voulez empêcher Googlebot d'accéder à tous les articles de votre blog, sauf un, votre directive pourrait ressembler à ceci :
User-agent: Googlebot
Disallow: /blog
Allow: /blog/example-postNote : Tous les moteurs de recherche ne reconnaissent pas cette commande. Mais Google et Bing prennent en compte cette directive.
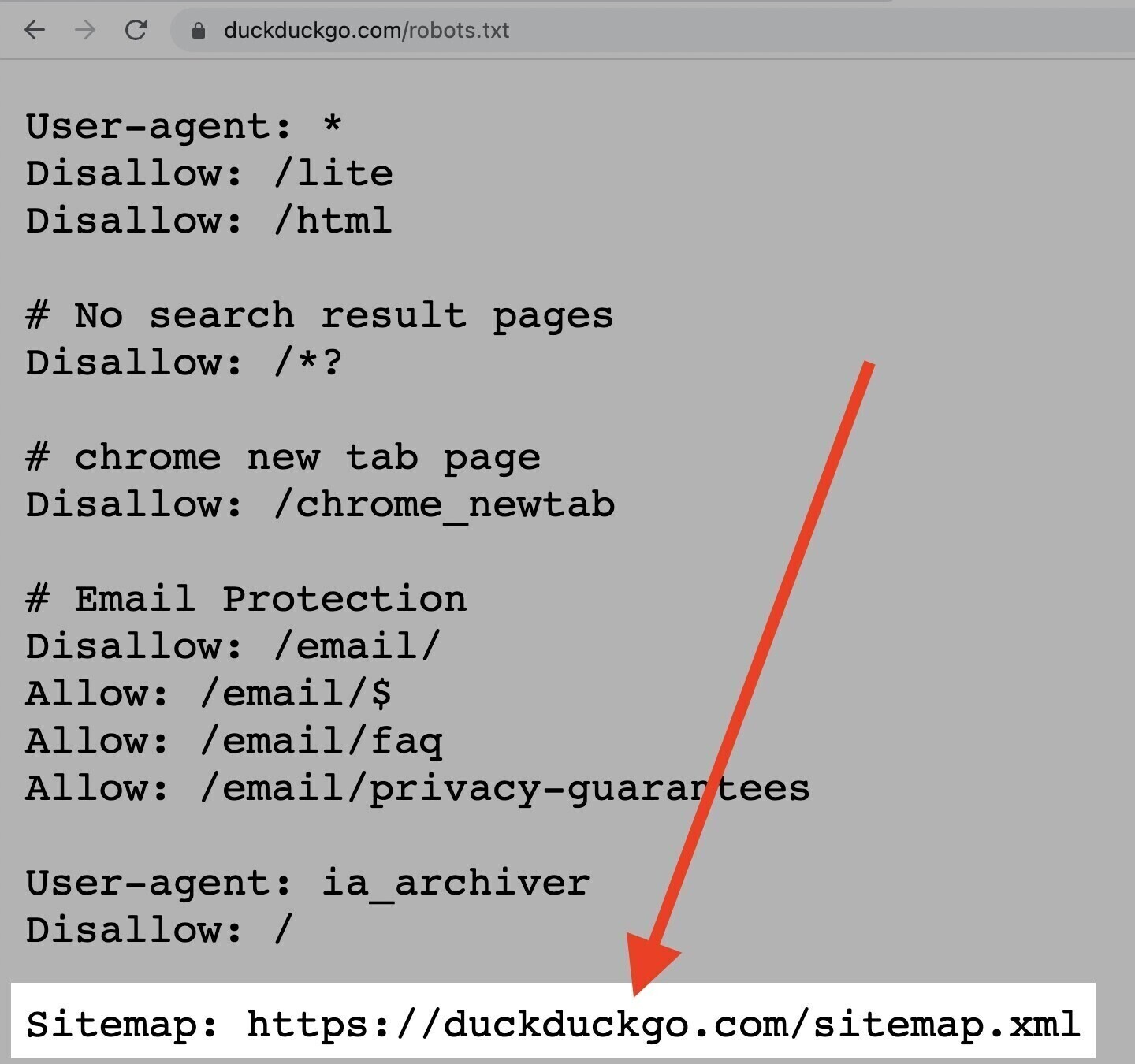
La directive Sitemap
La directive "Sitemap" indique aux moteurs de recherche, notamment Bing, Yandex et Google, où trouver votre sitemap XML.
Les sitemaps comprennent généralement les pages que vous souhaitez que les moteurs de recherche explorent et indexent.
Cette directive se trouve en haut ou en bas d'un fichier robots.txt et ressemble à ceci :
Cela dit, vous pouvez (et devez) également soumettre votre sitemap XML à chaque moteur de recherche à l'aide de leurs outils pour webmasters.
Les moteurs de recherche finiront bien par explorer votre site, mais la soumission d'un sitemap accélère le processus.
Si vous ne voulez pas le faire, l'ajout d'une directive "Sitemap" à votre fichier robots.txt est une bonne alternative rapide.
Directive crawl-delay
La directive "crawl-delay" spécifie un délai d'exploration en secondes. Elle est destinée à empêcher les robots d'exploration de surcharger un serveur (c'est-à-dire de ralentir votre site Web).
Toutefois, Google ne prend plus en charge cette directive.
Si vous souhaitez définir la vitesse d'exploration pour Googlebot, vous devez le faire dans la Search Console.
Bing et Yandex, en revanche, prennent en charge la directive crawl-delay.
Voici comment l'utiliser.
Si vous voulez qu'un crawler attende 10 secondes après chaque action d'exploration, vous pouvez définir le délai à 10, comme suit :
User-agent: *
Crawl-delay: 10Directive Noindex
Le fichier robots.txt indique à un robot ce qu'il peut ou ne peut pas explorer, mais il ne peut pas indiquer à un moteur de recherche les URL à ne pas indexer et à ne pas afficher dans les résultats de recherche.
La page apparaîtra quand même dans les résultats de recherche, mais le robot ne saura pas ce qu'elle contient, et votre page ressemblera donc à ceci :

Google n'a jamais officiellement reconnu cette directive, mais les professionnels du SEO pensaient qu'il suivait les instructions.
Cependant, le 1er septembre 2019, Google a été on ne peut plus clair : cette directive n'est pas prise en charge.
Si vous voulez exclure de manière fiable une page ou un fichier des résultats de recherche, évitez complètement cette directive et utilisez une balise meta robots noindex.
Comment créer un fichier Robots.txt
Si vous n'avez pas encore de fichier robots.txt, il est facile d'en créer un.
Vous pouvez utiliser un outil de génération de fichiers robots.txt ou le créer vous-même.
Voici comment créer un fichier robots.txt en quatre étapes seulement :
- Créez un fichier et nommez-le robots.txt
- Ajoutez des règles au fichier robots.txt
- Téléchargez le fichier robots.txt sur votre site
- Testez le fichier robots.txt
1. Créez un fichier et nommez-le robots.txt
Commencez par ouvrir un document .txt avec n'importe quel éditeur de texte ou navigateur web.
Note: N'utilisez pas de traitement de texte car ils enregistrent souvent les fichiers dans un format propriétaire qui peut ajouter des caractères aléatoires.
Ensuite, nommez le document robots.txt. Il doit être nommé robots.txt pour fonctionner.
Vous êtes maintenant prêt à commencer à saisir les directives.
2. Ajoutez des règles au fichier robots.txt
Un fichier robots.txt se compose d'un ou plusieurs groupes de directives, et chaque groupe est constitué de plusieurs lignes d'instructions.
Chaque groupe commence par un "User-agent" et comporte les informations suivantes :
- À qui s'applique le groupe (l'agent utilisateur)
- Les répertoires (pages) ou fichiers auxquels l'agent peut accéder
- Les répertoires (pages) ou fichiers auxquels l'agent ne peut pas accéder
- Un sitemap (facultatif) pour indiquer aux moteurs de recherche les pages et les fichiers que vous jugez importants
Les robots d'exploration ignorent les lignes qui ne correspondent à aucune de ces directives.
Par exemple, supposons que vous vouliez empêcher Google d'explorer votre répertoire /clients/ parce qu'il est réservé à un usage interne.
Le premier groupe ressemblerait à ceci :
User-agent: Googlebot
Disallow: /clients/Si vous aviez d'autres instructions de ce type pour Google, vous les incluriez dans une ligne distincte, juste en dessous, comme suit :
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-googleUne fois que vous en avez terminé avec les instructions spécifiques de Google, vous pouvez appuyer deux fois sur la touche Entrée pour créer un nouveau groupe de directives.
Créons celui-ci pour tous les moteurs de recherche et empêchons-les d'explorer vos répertoires /archive/ et /support/ parce qu'ils sont privés et réservés à un usage interne :
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/Une fois que vous avez terminé, vous pouvez ajouter votre sitemap.
Votre fichier robots.txt terminé devrait ressembler à quelque chose comme ceci :
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/
Sitemap: https://www.yourwebsite.com/sitemap.xmlEnregistrez votre fichier robots.txt. N'oubliez pas qu'il doit être nommé robots.txt (et pas autrement).
Note : Les crawlers lisent de haut en bas et répondent au premier groupe de règles le plus spécifique. Commencez donc votre fichier robots.txt par les agents utilisateurs spécifiques, puis passez au caractère générique (*) qui correspond à tous les crawlers.
3. Téléchargez le fichier robots.txt sur votre site
Après avoir enregistré votre fichier robots.txt sur votre ordinateur, chargez-le sur votre site et mettez-le à la disposition des moteurs de recherche pour qu'ils puissent l'explorer.
Malheureusement, il n'existe pas d'outil universel qui puisse vous aider dans cette étape.
Le téléchargement du fichier robots.txt dépend de la structure des fichiers de votre site et de votre hébergement.
Faites une recherche en ligne ou contactez votre hébergeur pour savoir comment télécharger votre fichier robots.txt.
Par exemple, vous pouvez rechercher "télécharger le fichier robots.txt sur WordPress" pour obtenir des instructions spécifiques.
Voici quelques articles expliquant comment télécharger votre fichier robots.txt dans les plateformes les plus populaires :
- Fichier Robots.txt dans WordPress
- Fichier Robots.txt dans Joomla
- Fichier Robots.txt dans Shopify
- Fichier Robots.txt dans BigCommerce
Après avoir téléchargé le fichier robots.txt, vérifiez si quelqu'un peut le voir et si Google peut le lire.
Voici comment procéder.
4. Testez le fichier robots.txt
Tout d'abord, vérifiez si votre fichier robots.txt est accessible au public (c'est-à-dire s'il a été téléchargé correctement).
Ouvrez une fenêtre privée dans votre navigateur et recherchez votre fichier robots.txt.
Par exemple, https://semrush.com/robots.txt.
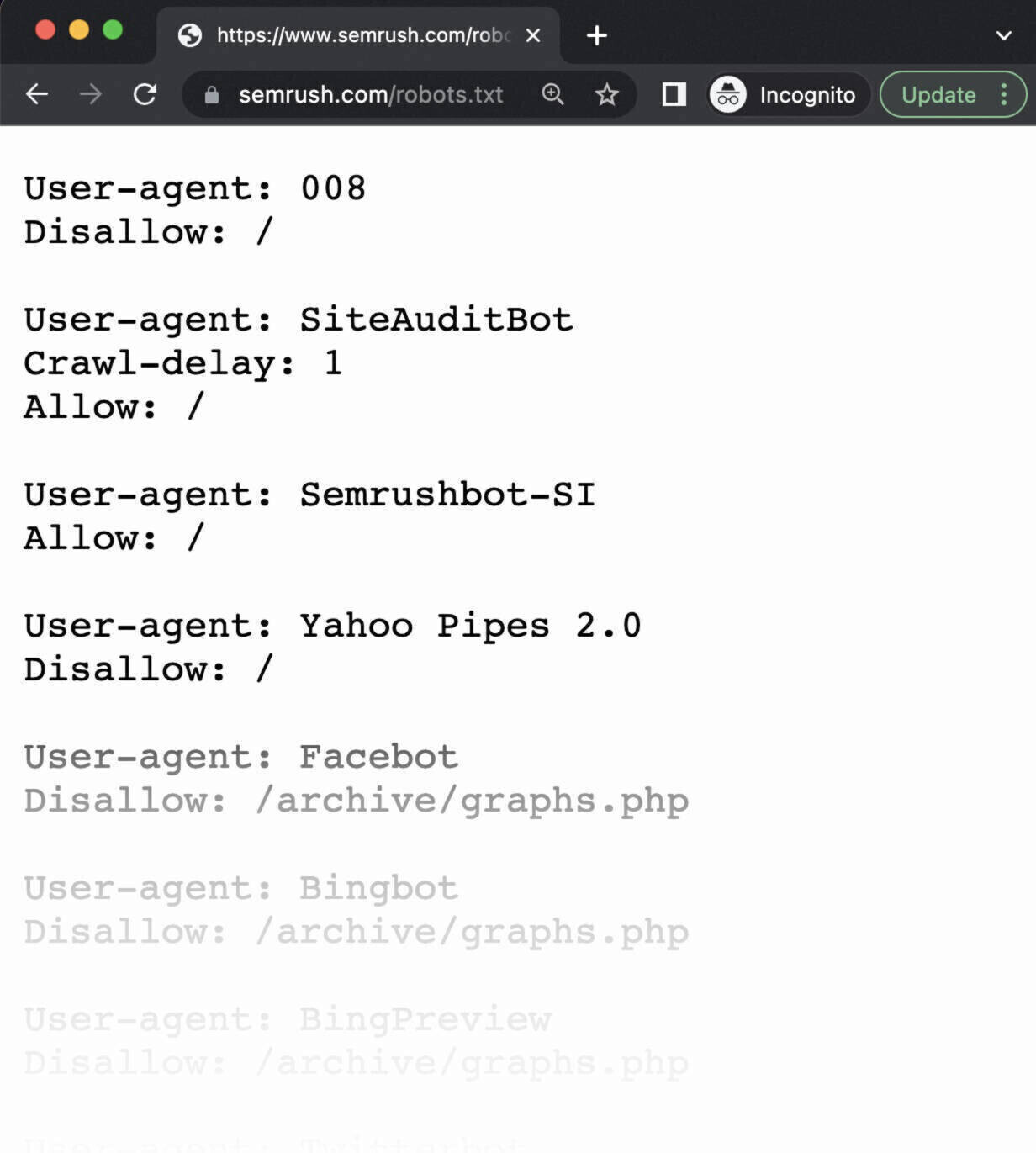
Si vous voyez votre fichier robots.txt avec le contenu que vous avez ajouté, vous êtes prêt à tester le balisage (code HTML).
Google propose deux options pour tester le balisage du robots.txt :
- L'outil de test du fichier robots.txt dans la Search Console
- La bibliothèque open source robots.txt de Google (avancé)
La deuxième option s'adressant davantage aux développeurs avancés, testons votre fichier robots.txt dans la Search Console.
Note : Vous devez avoir un compte Search Console configuré pour tester votre fichier robots.txt.
Allez dans le testeur de robots.txt et cliquez sur "Ouvrir l'outil de test du fichier robots.txt".

Si vous n'avez pas encore relié votre site Web à votre compte Google Search Console, vous devez d'abord ajouter une propriété.

Ensuite, vous devrez confirmer que vous êtes le véritable propriétaire du site.

Si vous avez des propriétés vérifiées existantes, sélectionnez-en une dans la liste déroulante de la page d'accueil de l'outil de test.
L'outil identifiera tous les avertissements de syntaxe ou les erreurs de logique et les mettra en évidence.
Il vous indiquera également le nombre d'avertissements et d'erreurs juste en dessous de l'éditeur.
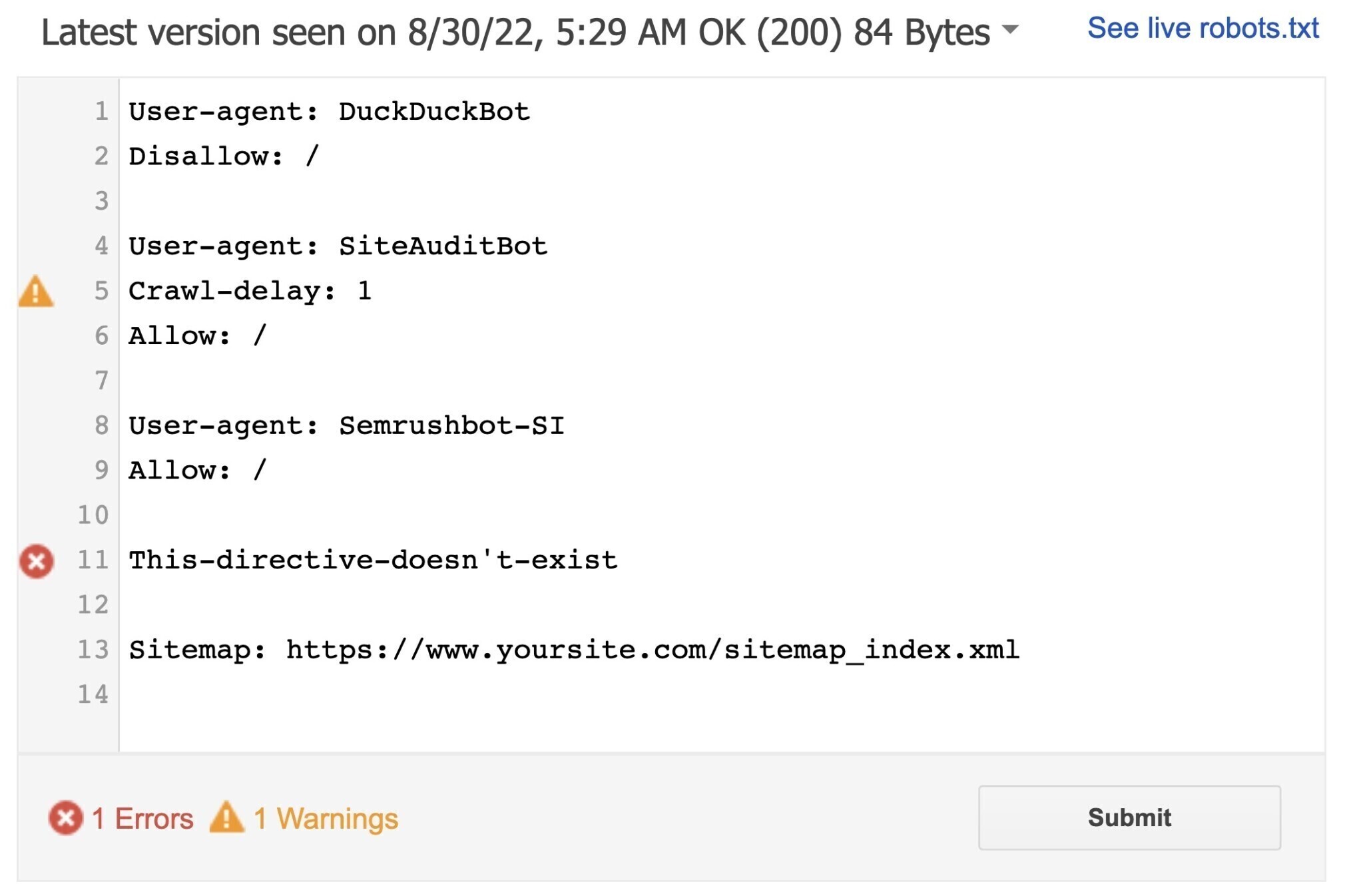
Vous pouvez traiter les erreurs ou les avertissements directement sur la page et retester autant de fois que nécessaire.
N'oubliez pas que les modifications apportées sur la page ne sont pas enregistrées sur votre site. L'outil n'apporte aucune modification au fichier réel sur votre site. Il ne teste que la copie hébergée dans l'outil.
Pour appliquer les modifications, copiez et collez-les dans le fichier robots.txt de votre site.
Conseil pro : Configurez des audits SEO techniques mensuels à l'aide de l'outil Audit de site pour vérifier l'absence de nouveaux problèmes concernant votre fichier robots.txt. Il est important de garder un œil sur votre fichier, car même des modifications mineures peuvent affecter négativement l'indexabilité de votre site.
Cliquez ici pour voir l'outil Audit de site de Semrush.
Meilleures pratiques pour le robots.txt
Gardez ces meilleures pratiques à l'esprit lorsque vous créez votre fichier robots.txt afin d'éviter les erreurs courantes.
Passez à la ligne pour chaque directive
Chaque directive doit être placée sur une nouvelle ligne.
Sinon, les moteurs de recherche ne seront pas en mesure de les lire et vos instructions seront ignorées.
Mauvais :
User-agent: * Disallow: /admin/
Disallow: /directory/Bon :
User-agent: *
Disallow: /admin/
Disallow: /directory/Utilisez chaque agent utilisateur une seule fois
Les robots n'ont rien contre le fait que vous saisissiez plusieurs fois le même agent utilisateur.
Mais ne le mentionner qu'une seule fois permet de simplifier les choses et de réduire les risques d'erreur humaine.
Mauvais :
User-agent: Googlebot
Disallow: /example-page
User-agent: Googlebot
Disallow: /example-page-2Remarquez que l'agent utilisateur Googlebot est mentionné deux fois.
Bon :
User-agent: Googlebot
Disallow: /example-page
Disallow: /example-page-2Dans le premier exemple, Google suivrait quand même les instructions et n'explorerait aucune des deux pages.
Mais écrire toutes les directives sous le même agent utilisateur est plus propre et vous aide à rester organisé.
Utilisez des caractères génériques pour clarifier les instructions
Vous pouvez utiliser des caractères génériques (*) pour appliquer une directive à tous les agents utilisateurs et faire correspondre des modèles d'URL.
Par exemple, si vous voulez empêcher les moteurs de recherche d'accéder aux URL contenant des paramètres, vous pouvez techniquement les énumérer un par un.
Mauvais :
User-agent: *
Disallow: /shoes/vans?
Disallow: /shoes/nike?
Disallow: /shoes/adidas?Mais ce n'est pas efficace. Vous pouvez simplifier vos indications avec un *.
Bon :
User-agent: *
Disallow: /shoes/*?L'exemple ci-dessus empêche tous les robots des moteurs de recherche d'explorer toutes les URL situées dans le sous-dossier /shoes/ avec un point d'interrogation.
Utiliser "$" pour indiquer la fin d'une URL
L'ajout du "$" indique la fin d'une URL.
Par exemple, si vous voulez empêcher les moteurs de recherche d'explorer tous les fichiers .jpg de votre site, vous pouvez les répertorier individuellement.
Mais ce ne serait pas efficace.
Mauvais :
User-agent: *
Disallow: /photo-a.jpg
Disallow: /photo-b.jpg
Disallow: /photo-c.jpgMais il est beaucoup plus rapide et plus clair d'utiliser le signe "$" comme ceci :
Bon :
User-agent: *
Disallow: /*.jpg$Note : Dans cet exemple, /dog.jpg ne peut pas être exploré, mais /dog.jpg?p=32414 peut l'être car il ne se termine pas par ".jpg".
L'expression "$" est une fonctionnalité utile dans des circonstances spécifiques comme ci-dessus, mais elle peut aussi être dangereuse.
Vous pouvez facilement débloquer des choses que vous n'aviez pas l'intention de faire, alors soyez prudent dans la façon dont vous l'appliquez.
Utilisez le dièse (#) pour ajouter des commentaires
Les robots ignorent tout ce qui commence par un dièse (#).
Les développeurs utilisent donc souvent un dièse pour ajouter un commentaire dans le fichier robots.txt. Cela permet de maintenir la bonne organisation du fichier et de faciliter sa lecture.
Pour inclure un commentaire, commencez la ligne par un dièse (#).
Comme ceci :
User-agent: *
#Pages de destination
Disallow: /landing/
Disallow: /lp/
#Fichiers
Disallow: /files/
Disallow: /private-files/
#Sites Web
Allow: /website/*
Disallow: /website/search/*Les développeurs incluent parfois des messages amusants dans les fichiers robots.txt, car ils savent que les utilisateurs les voient rarement.
Par exemple, dans le fichier robots.txt de YouTube, on peut lire :
“Créé dans un futur lointain (l'an 2000) après le soulèvement robotique du milieu des années 90 qui a éliminé tous les humains.”

Et dans le robots.txt de Nike, on trouve : “just crawl it” (une allusion à leur slogan “just do it”) et leur logo est également représenté.

Utilisez des fichiers Robots.txt distincts pour les différents sous-domaines
Les fichiers robots.txt ne contrôlent le comportement d'exploration que sur le sous-domaine où ils sont hébergés.
Ainsi, si vous souhaitez contrôler l'exploration d'un autre sous-domaine, vous devez créer un fichier robots.txt distinct.
Donc, si votre site principal se trouve sur domaine.com et votre blog sur le sous-domaine blog.domaine.com, vous aurez besoin de deux fichiers robots.txt.
Un pour le répertoire racine du domaine principal et l'autre pour le répertoire racine de votre blog.
Continuez à apprendre
Maintenant que vous avez une bonne compréhension du fonctionnement des fichiers robots.txt, voici quelques articles supplémentaires que vous pouvez lire pour continuer à apprendre :