
Certains éléments de contenu de votre site n'ont pas besoin d'être indexés par les moteurs de recherche. Pour empêcher l'indexation des pages nécessaires, vous pouvez utiliser une balise meta robot ou une directive X-Robots-Tag.
Cependant, il n'est pas rare que le fichier robots.txt et les balises meta robots soient mal utilisés. Il en résulte des directives désordonnées et contradictoires qui n'atteignent pas le résultat escompté, à savoir empêcher l'indexation d'une page.
Dans ce guide, nous voulons vous aider à comprendre comment utiliser les balises meta robots et la directive X-Robots-Tag afin de contrôler l'indexation du contenu de votre site et de vous aider à repérer les erreurs les plus courantes.
Plus précisément, nous allons nous pencher sur les éléments suivants :
- Définition des balises meta robots
- Explication des attributs et des directives des balises meta robots
- Exemples de codes de balises meta robots
- Utilisation des balises meta robots pour contrôler les extraits
- Définition de la directive X-Robots-Tag
- Configuration des balises meta robots et de la directive X-Robots-Tag
- Erreurs courantes des balises meta robots
Définition des balises meta robots
Une balise meta robots est un morceau de code HTML placé dans la section <head></head> d'une page web. Elle sert à contrôler la façon dont les moteurs de recherche explorent et indexent l'URL.
Voici à quoi ressemble une balise meta robots dans le code source d'une page :
<meta name="robots" content="noindex" />Ces balises sont spécifiques à chaque page et vous permettent d'indiquer aux moteurs de recherche comment vous voulez qu'ils traitent la page et si vous voulez ou non l'inclure dans l'index.
À quoi servent les balises meta robots ?
Les balises meta robots servent à contrôler la façon dont Google indexe le contenu de votre page web. Cela inclut les instructions suivantes :
- Inclure ou non une page dans les résultats de recherche
- Suivre ou non les liens d'une page (même si son indexation est bloquée)
- Demander de ne pas indexer les images d'une page
- Demander de ne pas afficher les résultats en cache de la page web sur les SERP
- Demander de ne pas afficher un extrait (meta description) pour la page sur les SERP
Afin de comprendre comment vous pouvez utiliser une balise meta robots, nous devons examiner les différents attributs et directives. Nous vous présenterons également des exemples de codes que vous pouvez prendre et déposer dans l'en-tête de votre page pour demander aux moteurs de recherche d'indexer votre page d'une certaine manière.
Explication des attributs et des directives des balises meta robots
L'utilisation des balises meta robots est assez simple une fois que vous avez compris comment définir les deux attributs : name et content. Ces deux attributs sont obligatoires, vous devez donc définir une valeur pour chacun d'entre eux.
Examinons ces attributs plus en détail.
Nom
L'attribut name contrôle le suivi par les robots et les bots (user-agents, également appelés chaînes de caractères user agent (UA) des instructions contenues dans la balise meta robots.
Pour donner comme consigne aux robots d'exploration de suivre les instructions, utilisez :
name="robots"Dans la plupart des scénarios, vous voudrez l'utiliser par défaut, mais vous pouvez utiliser autant de balises meta robots différentes que nécessaire pour spécifier les instructions aux différents robots d'exploration.
Lorsque l'on donne des consignes à différents robots d'exploration, il s'agit simplement d'utiliser plusieurs balises :
<meta name="googlebot" content="noindex">
<meta name="googlebot-news" content="nosnippet">Il existe des centaines d'agents utilisateurs différents. Les plus courants sont les suivants :
- Google : Googlebot (vous trouverez une liste complète des robots d'exploration de Google ici)
- Bing : Bingbot (vous trouverez une liste complète des robots d'exploration de Bing ici)
- DuckDuckGo : DuckDuckBot
- Baidu : Baiduspider
- Yandex : YandexBot
Contenu
L'attribut content vous sert à donner les instructions à l'agent utilisateur spécifié.
Il est important de savoir que si vous ne spécifiez pas de balise meta robots sur une page Web, la valeur par défaut est d'indexer la page et de suivre tous les liens (sauf s'ils ont un attribut rel="nofollow" spécifié en ligne).
Parmi les différentes directives que vous pouvez utiliser, on trouve :
- index (inclure la page dans l'index) [Note : il n'est pas nécessaire de l'inclure si la valeur noindex n'est pas spécifiée, il est supposé être un index)
- noindex (ne pas inclure la page dans l'index ou l'afficher sur les SERP)
- follow (suivre les liens de la page pour découvrir d'autres pages)
- nofollow (ne pas suivre les liens sur la page)
- none (raccourci pour spécifier les valeurs noindex, nofollow)
- all (raccourci pour spécifier les valeurs index, follow)
- noimageindex (ne pas indexer les images de la page)
- noarchive (ne pas afficher une version en cache de la page sur les SERP)
- nocache (c'est la même chose que noarchive, mais pour MSN)
- nositelinkssearchbox (ne pas afficher une zone de recherche pour votre site sur les SERP)
- nopagereadaloud (ne pas autoriser les services vocaux à lire votre page à voix haute)
- notranslate (ne pas afficher les traductions de la page sur les SERP)
- unavailable_after (spécifier un délai au bout duquel la page ne doit pas être indexée)
Vous pouvez voir la liste complète des directives que Google prend en charge ici et celles que Bing prend en charge ici.
Exemples de codes de balises meta robots
Si vous recherchez des exemples de balises meta robots que vous pouvez utiliser pour contrôler la façon dont les moteurs de recherche explorent et indexent vos pages, vous pouvez utiliser le tableau ci-dessous qui présente les scénarios d'utilisation les plus courants :
Ne pas indexer la page mais suivre les liens vers d'autres pages :
<meta name="robots" content="noindex, follow" />Ne pas indexer la page et ne pas suivre les liens vers d'autres pages :
<meta name="robots" content="none" />Indexer la page mais ne pas suivre les liens vers d'autres pages :
<meta name="robots" content="nofollow" />Ne pas afficher une copie du cache des pages sur les SERP :
<meta name="robots" content="noarchive" />Ne pas indexer les images d'une page :
<meta name="robots" content="noimageindex" /Ne pas afficher la page sur les SERP après une date/heure précise :
<meta name="robots" content="unavailable_after: Friday, 01-Jan-21 12:59:59 ET" />Au besoin, vous pouvez combiner les directives en une seule balise, en les séparant par des virgules.
Par exemple, disons que vous ne voulez pas qu'un des liens d'une page soit suivi et que vous voulez aussi empêcher l'indexation des images. Utilisez :
<meta name="robots" content="nofollow, noimageindex" /Utilisation des balises meta robots pour contrôler les extraits
Si les balises meta robots sont le plus souvent utilisées pour contrôler l'indexation ou non d'une page et l'exploration ou non des liens de cette page par les moteurs de recherche, elles peuvent également servir à contrôler les extraits (snippets) sur les SERP.
Introduites en septembre 2019, Google a expliqué que les webmasters pouvaient grâce à elles utiliser « un ensemble de méthodes qui permettent une configuration plus fine du contenu de l'aperçu affiché pour vos pages. »
Ces méthodes se présentent sous la forme des balises meta robots suivantes :
- nosnippet (ne pas afficher d'extrait/meta description pour la page sur les SERP)
- max-snippet:[nombre] (spécifier la longueur maximale du texte d'un extrait en caractères)
- max-video-preview:[number] (spécifier la durée maximale d'un aperçu vidéo en secondes)
- max-image-preview:[setting] (spécifier la taille maximale d'un aperçu d'image soit "none," "standard," ou "large")
Utilisez le code suivant pour contrôler la façon dont les extraits de votre page web sont affichés :
Ne pas afficher d'extraits de page sur les SERP :
<meta name="robots" content="nosnippet" />Définissez la longueur maximale d'un extrait de texte à 150 caractères :
<meta name="robots" content="max-snippet:150" />Définissez la durée maximale d'un aperçu vidéo à 20 secondes :
<meta name="robots" content="max-video-preview:30" />Définissez la taille maximale de l'aperçu d'une image à grande échelle :
<meta name="robots" content="max-image-preview:large" />Ils peuvent également être combinés pour donner un meilleur contrôle sur les extraits de votre page. Supposons que vous vouliez fixer la longueur maximale de votre extrait à 150 caractères et autoriser les aperçus d'images de grande taille, utilisez :
<meta name="robots" content="max-snippet:150, max-image-preview:large" />Si vous avez une audience en France, vous devez être très attentif à ces balises car la loi française sur les droits d'auteur empêche Google d'afficher des extraits de votre site web, à moins que vous ne choisissiez de les utiliser.
Si vous ne souhaitez pas imposer de restrictions à vos extraits, vous pouvez ajouter les éléments suivants dans l'en-tête de votre page :
<meta name="robots" content="max-snippet:-1, max-image-preview:large, max-video-preview:-1" />Définition de la directive X-Robots-Tag
Une autre façon de contrôler la façon dont les moteurs de recherche explorent et indexent vos pages web est d'utiliser la directive X-Robots-Tag plutôt que les balises meta robots.
Alors que l'implémentation de balises meta robots dans les pages HTML est relativement simple, celle de la directive X-Robots-Tag est plus compliquée. Si vous souhaitez contrôler la manière dont le contenu non-HTML est traité, par exemple un PDF, vous devrez utiliser la directive R-robots-Tag.
Il s'agit d'une réponse d'en-tête HTTP, plutôt que d'une balise HTML, et toute directive qui peut être utilisée comme balise meta robots peut également être utilisée comme balise x-robots.
Voici un exemple de ce à quoi ressemble une réponse d'en-tête X-robots-Tag :
x-robots-tag : noindex, nofollowPour utiliser la balise x-robots, vous devez pouvoir accéder à l'en-tête de votre site web .php, .htaccess ou au fichier de configuration du serveur. Si vous n'y avez pas accès, vous devrez utiliser des balises meta robots pour donner des instructions aux robots d'exploration.
Quand utiliser la directive X-Robots-Tag ?
L'utilisation d'une balise X-robots n'est pas aussi simple que celle des balises meta robots, mais elle permet d'indiquer aux moteurs de recherche comment indexer et explorer d'autres types de fichiers.
Utilisez la directive X-robots-Tag quand :
- Vous devez contrôler la façon dont les moteurs de recherche explorent et indexent les types de fichiers non-HTML
- Vous devez servir les directives au niveau mondial (à l'échelle du site) plutôt qu'au niveau de la page
Configuration des balises meta robots et de la directive X-Robots-Tag
Il est généralement plus facile de configurer des méta de robots que des balises x-robots, mais la mise en œuvre de ces deux méthodes de contrôle de l'exploration et de l'indexation de votre site par les moteurs de recherche peut varier en fonction de votre CMS et/ou du type de serveur.
Voici comment utiliser les balises meta robots et les balises X-robots sur les configurations courantes :
- Utilisation des balises meta robots dans le code HTML
- Utilisation des balises meta robots sur WordPress
- Utilisation des balises meta robots sur Shopify
- Utilisation de la directive X-Robots-Tag sur un serveur Apache
- Utilisation de la directive X-Robots-Tag sur un serveur Nginx
Utilisation des balises meta robots dans le code HTML
Si vous pouvez modifier le code HTML de votre page, il vous suffit d'ajouter les balises meta robots directement dans la section <head> de la page.
Si vous souhaitez que les moteurs de recherche n'indexent pas la page mais qu'ils suivent les liens, utilisez par exemple :
<meta name="robots" content="noindex, follow" />Utilisation des balises meta robots sur WordPress
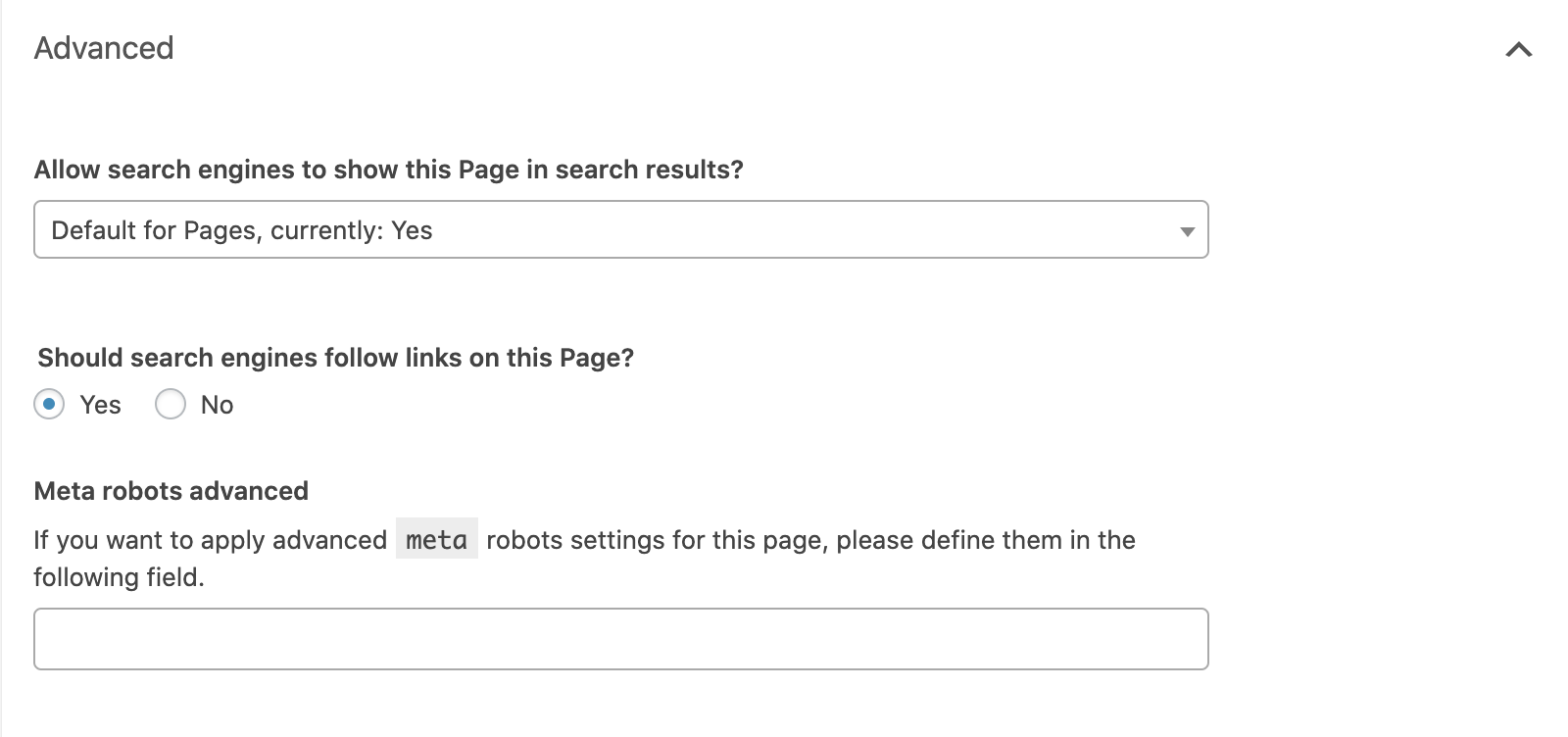
Si vous utilisez Yoast SEO, ouvrez l'onglet « avancé » dans le bloc situé sous l'éditeur de page.
Vous pouvez définir la directive "noindex" en définissant la liste déroulante "Allow search engines to show this page in search results ?" sur no ou empêcher les liens d'être suivis en définissant "Should search engines follow links on this page?" sur no.
Pour toute autre directive, vous devrez les mettre en œuvre dans le champ "Meta robots advanced" field.
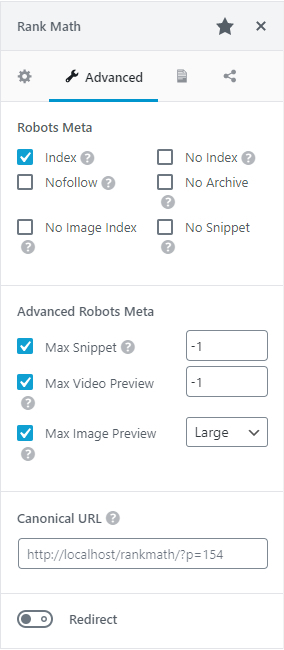
Si vous utilisez RankMath, vous pouvez sélectionner les directives des robots que vous souhaitez appliquer directement à partir de la balise Advanced de l'encadré meta :
Utilisation des balises meta robots sur Shopify
Si vous avez besoin d'implémenter les balises meta robots sur Shopify, vous devrez le faire en modifiant la section <head> de votre fichier de mise en page theme.liquid.
Pour définir les directives pour une page spécifique, ajoutez le code ci-dessous à ce fichier :
{% if handle contains 'page-name' %}
<meta name="robots" content="noindex, follow">
{% endif %}Ce code indiquera aux moteurs de recherche de ne pas indexer /page-name/ mais de suivre tous les liens de la page.
Vous devrez faire des entrées séparées pour définir les directives sur différentes pages.
Utilisation de la directive X-Robots-Tag sur un serveur Apache
Pour utiliser la balise x-robots sur un serveur web Apache, ajoutez ce qui suit au fichier .htaccess ou au fichier httpd.config de votre site.
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex, follow"
</Files>L'exemple ci-dessus définit le type de fichier .pdf et indique aux moteurs de recherche de ne pas indexer le fichier mais de suivre les liens qu'il contient.
Utilisation de la directive X-Robots-Tag sur un serveur Nginx
Si vous utilisez un serveur Nginx, ajoutez ce qui suit au fichier .conf de votre site :
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, follow";
}Cela permettra d'appliquer un attribut noindex et de suivre les liens éventuels d'un fichier .pdf.
Erreurs courantes des balises meta robots
Il n'est pas rare que des erreurs soient commises lorsque l'on indique aux moteurs de recherche d'explorer et d'indexer une page web, la plus courante étant la suivante :
- Blocage des directives des balises meta robots sur une page par Robots.txt
- Ajout de directives sur les robots au fichier robots.txt
- Suppression des pages comportant une directive noindex des plans de site
- Blocage accidentel des moteurs de recherche lors de l'exploration d'un site entier
Blocage des directives des balises meta robots sur une page par Robots.txt
Si une page est interdite dans votre fichier robots.txt, les robots des moteurs de recherche ne pourront pas explorer la page et prendre note de toute directive placée dans les balises meta robots ou dans une balise x-robots.
Veillez à ce que toutes les pages qui donnent des instructions aux agents utilisateurs de cette manière peuvent être explorées.
Si une page n'a jamais été indexée, une règle d'interdiction de robots.txt devrait suffire pour empêcher que cela ne s'affiche dans les résultats de recherche, mais il est tout de même recommandé d'ajouter une balise meta robots.
Ajout de directives sur les robots au fichier robots.txt
Bien que cela n'ait jamais été officiellement pris en charge par Google, il était possible d'ajouter une directive "noindex" au fichier robots.txt de votre site et de la faire appliquer.
Ce n'est plus le cas, chose qui a été confirmé par Google en 2019.
Suppression des pages comportant une directive noindex des plans de site
Si vous essayez de supprimer une page de l'index en utilisant une directive "noindex", laissez la page dans le plan du site jusqu'à ce que cela soit fait.
Le fait de supprimer la page avant qu'elle n'ait été désindexée peut entraîner des retards dans ce processus.
Blocage accidentel des moteurs de recherche lors de l'exploration d'un site entier
Malheureusement, il n'est pas rare que les directives relatives aux robots utilisées dans un environnement intermédiaire soient laissées en place par accident lorsque le site passe sur un serveur en direct, et les résultats peuvent être désastreux.
Avant de migrer un site d'une plateforme intermédiaire vers un environnement réel, vérifiez que les directives relatives aux robots qui sont en place sont correctes.
Vous pouvez utiliser l'outil Audit de site de Semrush avant de migrer vers une plateforme en direct pour trouver les pages qui sont bloquées soit par des balises meta robots soit par la directive X-robots-Tag.
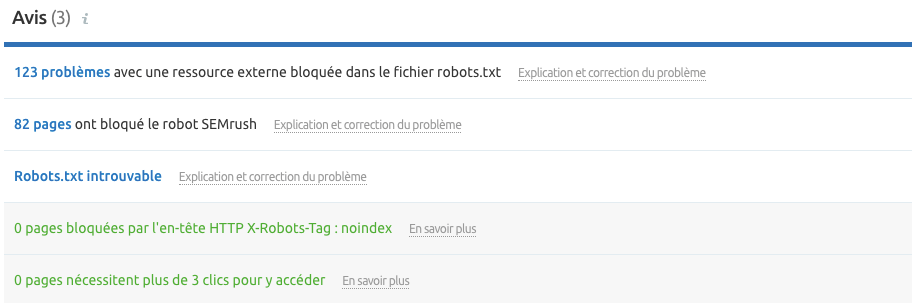
En prenant le temps de comprendre les différentes directives et la manière de les utiliser, vous pouvez éviter les erreurs techniques de référencement. Avoir un contrôle suffisant de la façon dont vos pages sont explorées et indexées peut, entre autres, aider à faire en sorte que les pages non souhaitées restent en hors des SERP, empêcher les moteurs de recherche de suivre des liens inutiles et vous donner le contrôle sur la façon dont les extraits de votre site s'affichent. Commencez à configurer vos balises meta robots et x-robots pour assurer le bon fonctionnement de votre site !